データを効率的に検索し、処理する能力は、今日の技術集約的な時代において、ゲームチェンジャーとなっている。 RAG APIがデータ処理をどのように再定義するのかを探ってみよう。 この革新的なアプローチは、大規模言語モデル(Large Language Models:LLM)と検索ベースの技術を組み合わせ、データ検索に革命をもたらす。
大規模言語モデル(LLM)とは?
大規模言語モデル(LLM)は、検索拡張世代(RAG)の基盤となる高度な人工知能システムである。 GPT(Generative Pre-trained Transformer)のようなLLMは、高度に洗練された言語駆動型AIモデルである。 彼らは広範なデータセットで訓練されており、人間のようなテキストを理解し、生成することができる。
VIDEO
RAG APIの文脈では、これらのLLMはデータ検索、処理、生成の強化において中心的な役割を果たし、データ相互作用を最適化するための多用途で強力なツールとなっている。
RAG APIのコンセプトを簡単に説明しよう。
RAGとは? RAG(Retrieval-AugmentedGeneration)は、生成AIを最適化するために設計されたフレームワークである。 その主な目的は、AIによって生成される回答が、入力プロンプトに対して最新かつ適切であるだけでなく、正確であることを保証することである。 この正確さへのこだわりは、RAG APIの機能の重要な側面である。 これは、GPTのようなラージ・ランゲージ・モデル(LLM)と呼ばれる超スマートなコンピューター・プログラムを使ってデータを処理する画期的な方法である。
VIDEO
これらのLLMは、その前の単語を理解することによって、文の中で次に来る単語を予測することができるデジタル魔法使いのようなものだ。 彼らは膨大な量のテキストから学んでいるので、とても人間らしく聞こえるように書くことができる。 RAGでは、これらのデジタルウィザードを使用して、カスタマイズされた方法でデータを検索し、作業することができます。 データについて何でも知っている本当に賢い友人に助けてもらっているようなものだ!
基本的に、RAGはセマンティック検索で取得したデータを、LLMへのクエリに注入して参照する。 これらの用語については、記事の中でさらに掘り下げていく。
RAGについてもっと詳しく知りたい方は、Cohereの 包括的な記事をご覧ください。
RAG vs. ファインチューニング:その違いは?
アスペクト RAG API 微調整
アプローチ 既存のLLMをデータベースのコンテキストで補強 特定の業務に特化したLLM
計算リソース 少ない計算資源で済む かなりの計算資源を必要とする
データ要件 小規模なデータセットに適している 膨大なデータを必要とする
モデルの特異性 機種にとらわれず、必要に応じて機種変更が可能 LLMの切り替えは通常非常に面倒である。
ドメイン適応性 ドメインにとらわれず、様々なアプリケーションに対応可能 異なるドメインに適応する必要があるかもしれない
幻覚軽減 幻覚を抑える効果 注意深く調整しないと、幻覚が増える可能性がある。
一般的な使用例 質疑応答(QA)システム、各種アプリケーションに最適 医療文書分析などの専門業務
ベクター・データベースの役割 ベクトル・データベースは、検索補強型生成(RAG)や大規模言語モデル(LLM)において極めて重要である。 これらは、データ検索、コンテキストの補強、およびこれらのシステムの全体的なパフォーマンスを向上させるためのバックボーンとして機能する。 ここでは、ベクター・データベースの重要な役割を探る:
構造化データベースの制限を克服する 従来の構造化データベースは、RAG APIで使用する場合、その硬直的であらかじめ定義された性質のために、不足することが多い。 LLMに文脈情報を与えるという柔軟で動的な要求に対応するのに苦労している。 ベクター・データベースは、この制限に対処するために導入された。
ベクトル形式のデータの効率的な保存 ベクトルデータベースは、数値ベクトルを使ったデータの保存と管理に優れています。 このフォーマットは、多目的で多次元的なデータ表現を可能にする。 これらのベクトルは効率的に処理することができ、高度なデータ検索を容易にする。
データの妥当性とパフォーマンス RAGシステムは、ベクトルデータベースを活用することで、関連するコンテキスト情報に素早くアクセスし、検索することができる。 この効率的な検索は、LLMが応答を生成するスピードと精度を高めるために極めて重要である。
クラスタリングと多次元分析 ベクトルは、多次元空間のデータポイントをクラスタリングして分析することができる。 この機能はRAGにとって非常に貴重で、コンテクストデータをグループ化し、関連付け、LLMに首尾一貫して提示することができる。 これは、より良い理解と文脈を考慮した応答の生成につながる。
セマンティック検索とは? 意味検索は、RAG(Retrieval-Augmented Generation)APIやLLM(Large Language Models)の要である。 情報へのアクセスや理解の仕方に革命をもたらしたその意義は、いくら強調してもしすぎることはない。
従来のデータベースを超える セマンティック検索は、しばしば動的で柔軟なデータ要件の処理に苦労する構造化データベースの限界を超える。 その代わりに、ベクターデータベースを利用することで、RAGとLLMの成功に不可欠な、より多用途で適応性のあるデータ管理を可能にしている。
多次元分析 セマンティックサーチの重要な強みの一つは、データを数値ベクトルの形で理解する能力である。 この多次元分析は、コンテキストに基づくデータ関係の理解を強化し、より首尾一貫した、コンテキストを考慮したコンテンツ生成を可能にする。
効率的なデータ検索 データ検索、特にRAG APIシステムにおけるリアルタイムのレスポンス生成には効率が不可欠である。 セマンティック検索はデータアクセスを最適化し、LLMを使った回答生成の速度と精度を大幅に向上させる。 医療分析から複雑なクエリまで、さまざまな用途に適応できる汎用性の高いソリューションであると同時に、AIが生成するコンテンツの不正確さを低減する。
RAG APIとは?
RAG APIをRAG-as-a-Serviceとして考えて みよう。 RAGシステムのすべての基本を1つのパッケージにまとめたもので、あなたの組織でRAGシステムを採用するのに便利です。 RAG APIを使用することで、RAGシステムの主要な要素に集中し、残りをAPIに処理させることができます。
RAG APIクエリの3つの要素とは?
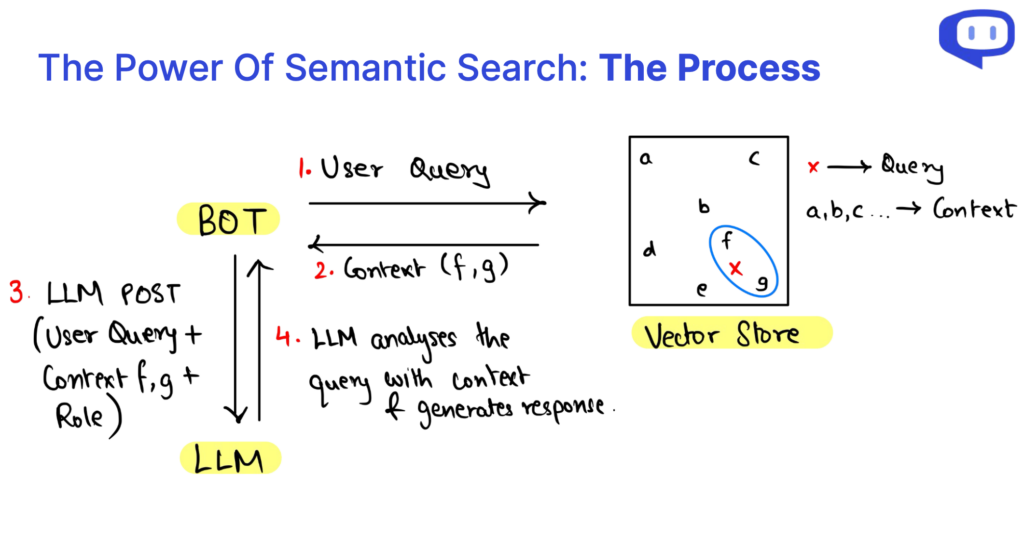
RAG(Retrieval-Augmented Generation)の複雑さを掘り下げていくと、RAGクエリは3つの重要な要素に分解できることがわかる: コンテキスト、役割、そしてユーザークエリ。 これらのコンポーネントは、RAGシステムを動かす構成要素であり、それぞれがコンテンツ生成プロセスにおいて重要な役割を果たしている。
について コンテクスト はRAG APIクエリの基礎を形成し、重要な情報が存在するナレッジリポジトリの役割を果たす。 既存の知識ベース・データにセマンティック検索を活用することで、ユーザーのクエリに関連したダイナミックなコンテキストが可能になる。
その 役割 は、RAGシステムの目的を定義し、特定のタスクを実行するよう指示する。 要件に合わせたコンテンツを生成したり、説明を提供したり、問い合わせに答えたり、情報を要約したりする際に、モデルをガイドする。
ユーザー ユーザークエリ はユーザーの入力であり、RAGプロセスの開始を示す。 ユーザーとシステムとのインタラクションを表し、ユーザーの情報ニーズを伝える。
RAG API内のデータ検索プロセスは、セマンティック検索によって効率化されている。 このアプローチは、多次元的なデータ分析を可能にし、コンテキストに基づくデータ関係の理解を向上させる。 一言で言えば、RAGクエリとセマンティック検索によるデータ検索の解剖学的構造を把握することで、この技術の潜在能力を解き放ち、効率的な知識アクセスとコンテキストを考慮したコンテンツ生成を促進することができる。
プロンプトで関連性を高めるには? プロンプトエンジニアリングは、RAG内の大規模言語モデル(LLM)を操作して、特定のドメインに文脈に関連した応答を生成する上で極めて重要である。
コンテキストを活用するRAG(Retrieval-Augmented Generation)の能力は恐ろしいものだが、高品質の回答を確保するためには、コンテキストを提供するだけでは必ずしも十分ではない。 そこで、プロンプトという概念が登場する。
よく練られたプロンプトは、LLMのロードマップの役割を果たし、望ましい反応へと導く。 通常、以下の要素が含まれる:
文脈の関連性を解き明かす 検索補強世代(RAG)は、コンテキストを活用するための強力なツールである。 しかし、質の高い回答を保証するには、単なる文脈だけでは不十分かもしれない。 これは、RAG内の大規模言語モデル(LLM)が特定のドメインに沿った応答を生成するように誘導する上で、プロンプトが非常に重要であることを示している。
ユースケースに合わせたボット役割構築のロードマップ うまく構成されたプロンプトは、LLMを望ましい回答へと導くロードマップの役割を果たす。 通常、さまざまな要素で構成されている:
ボットの正体 ボットの名前を出すことで、対話の中でボットのアイデンティティを確立し、会話をよりパーソナルなものにすることができる。
タスクの定義 LLMが実行すべきタスクや機能を明確に定義することで、情報の提供、質問への回答、その他の特定のタスクなど、ユーザーのニーズを確実に満たすことができる。
音色仕様 希望するトーンや応答スタイルを指定することで、フォーマル、フレンドリー、情報提供など、対話の適切なムードが設定される。
その他の指示 このカテゴリーには、リンクや画像の追加、挨拶の提供、特定のデータの収集など、さまざまな指示が含まれます。
文脈との関連性を作る 熟考してプロンプトを作成することは、RAGとLLMの相乗効果により、文脈を意識した、ユーザーの要求に非常に適切な回答が得られるようにする戦略的アプローチであり、全体的なユーザーエクスペリエンスを向上させる。
コーディーのRAG APIを選ぶ理由 さて、RAGの意義とその核となるコンポーネントを紐解いたところで、RAGを実現するための究極のパートナーとしてコーディを紹介しよう。 Codyは 、効率的なデータ検索と処理に必要なすべての重要な要素を組み合わせた包括的なRAG APIを提供して おり、RAGの旅に最適な選択肢となっています。
モデルにとらわれない
最新のAIトレンドに対応するためにモデルを切り替える心配はない。 CodyのRAG APIを使えば、追加コストなしで、大規模な言語モデルをオンザフライで簡単に切り替えることができます。
比類なき汎用性 CodyのRAG APIは、さまざまなファイル形式を効率的に処理し、最適なデータ編成のためにテキスト階層を認識するなど、優れた汎用性を発揮する。
カスタムチャンキングアルゴリズム その際立った特徴は、高度なチャンキング・アルゴリズムにあり、メタデータを含む包括的なデータ・セグメンテーションを可能にし、優れたデータ管理を保証する。
比較にならないスピード インデックスの数に関係なく、直線的なクエリ時間で、大規模なデータ検索を確実に高速化します。 お客様のデータニーズに迅速な結果を保証します。
シームレスな統合とサポート Codyは、一般的なプラットフォームとのシームレスな統合と包括的なサポートを提供し、お客様のRAGエクスペリエンスを向上させ、効率的なデータ検索と処理のトップチョイスとしての地位を確固たるものにします。 技術的な専門知識を必要としない直感的なユーザー・インターフェイスは、あらゆるレベルの人にとってアクセスしやすく使いやすいものであり、データの検索と処理をさらに効率化する。
データ・インタラクションを高めるRAG API機能 RAG(Retrieval-AugmentedGeneration)の探求において、私たちは大規模言語モデル(LLM)をセマンティック検索、ベクトルデータベース、プロンプトと統合し、データ検索と処理を強化する多用途なソリューションを発見した。
モデルにとらわれず、領域にもとらわれないRAGは、多様なアプリケーションにおいて大きな可能性を秘めている。 CodyのRAG APIは、柔軟なファイル操作、高度なチャンキング、迅速なデータ検索、シームレスな統合といった機能を提供することで、この約束をさらに高めている。 この組み合わせは、データ・エンゲージメントに革命を起こそうとしている。
このデータ・トランスフォーメーションを受け入れる準備はできているだろうか? Cody AIで 、データ・インタラクションを再定義し、データ処理の新時代を切り拓こう。
よくあるご質問
1.RAGと大規模言語モデル(LLM)の違いは?
RAG API(Retrieval-Augmented Generation API)とLLM(Large Language Models)は連携して動作する。
RAG APIは、検索メカニズムと生成言語モデル(LLM)という2つの重要な要素を組み合わせたアプリケーション・プログラミング・インターフェースである。 その主な目的は、データ検索とコンテンツ生成を強化することであり、特にコンテキストを意識した対応に重点を置いている。 RAG APIは、質問応答、コンテンツ生成、テキスト要約などの特定のタスクに適用されることが多い。 これは、ユーザーのクエリに対して、文脈に関連した回答をもたらすように設計されている。
一方、LLM(Large Language Models)は、GPT(Generative Pre-trained Transformer)のような、より広範な言語モデルのカテゴリーを構成する。 これらのモデルは広範なデータセットで事前に訓練されており、様々な自然言語処理タスクに対して人間のようなテキストを生成することができる。 検索と生成に対応する一方で、その汎用性は翻訳、感情分析、テキスト分類など、さまざまな用途に広がっている。
要するに、RAG APIは、特定のアプリケーションにおけるコンテキストを考慮した応答のために、検索と生成を組み合わせた特別なツールである。 対照的に、LLMは様々な自然言語処理タスクの基礎となる言語モデルであり、検索や生成だけでなく、より広範な応用の可能性を提供する。
2.RAGとLLM-何が良いのか、なぜ良いのか?
RAG APIとLLMのどちらを選ぶかは、特定のニーズと達成しようとするタスクの性質による。 ここでは、あなたの状況にどちらが適しているかを判断するのに役立つ考慮事項の内訳を説明する:
RAG API Ifを選択する:
コンテキストを意識した対応が必要
RAG APIは、文脈に関連した回答を提供することに優れている。 もしあなたのタスクが質問に答えたり、内容を要約したり、文脈に応じた応答を生成したりするのであれば、RAG APIは適切な選択である。
具体的な使用例
あなたのアプリケーションやサービスが、コンテキストを意識したコンテンツを必要とする、明確に定義されたユースケースを持っているなら、RAG APIがより適しているかもしれない。 これは、コンテキストが重要な役割を果たすアプリケーションのために作られている。
微調整が必要
RAG APIは微調整やカスタマイズが可能で、プロジェクトに特定の要件や制約がある場合に有利です。
LLMを選ぶなら
求められるのは多用途性
LLMはGPTモデルと同様、汎用性が高く、自然言語処理タスクを幅広く扱うことができる。 ニーズが複数の用途にまたがる場合、LLMは柔軟性を提供する。
カスタムソリューションを構築したい
カスタムの自然言語処理ソリューションを構築し、特定のユースケースに合わせて微調整したり、既存のワークフローに統合したりすることができます。
事前に訓練された言語理解が必要
LLMは膨大なデータセットで事前に訓練されているため、すぐに強力な言語理解力を発揮する。 大量の非構造化テキストデータを扱う必要がある場合、LLMは貴重な資産となる。
3.なぜGPTモデルのようなLLMが自然言語処理で人気なのか? LLMは、様々な言語タスクにおいて卓越したパフォーマンスを発揮することから、広く注目を集めている。 LLMは大規模なデータセットで学習される。 その結果、あらゆる言語のニュアンスを理解することで、首尾一貫した、文脈に即した、文法的に正しい文章を理解し、作成することができる。 さらに、事前に訓練されたLLMを利用できるようになったことで、AIによる自然言語理解と生成がより多くの人にとって身近なものになった。
4.LLMの典型的な応用例とは?
LLMは、以下のような幅広い言語タスクに応用されている:
自然言語理解
LLMは、感情分析、名前付きエンティティ認識、質問応答などのタスクを得意とする。 その強力な言語理解能力により、テキストデータから洞察を抽出するのに重宝される。
テキスト生成
チャットボットやコンテンツ生成のようなアプリケーションのために人間のようなテキストを生成し、首尾一貫した、文脈に関連した応答を提供することができる。
機械翻訳
機械翻訳の品質を大幅に向上させた。 彼らは驚くべき正確さと流暢さで言語間のテキストを翻訳することができる。
コンテンツの要約
長い文書やトランスクリプトを簡潔に要約することに長けており、膨大なコンテンツから必要な情報を抽出する効率的な方法を提供します。
5.LLMはどのようにして新鮮なデータと進化する課題に対応し続けることができるのか? LLMが最新かつ効果的であり続けるようにすることは極めて重要である。 新しいデータや進化するタスクに対応するために、いくつかの戦略が採用されている:
データ補強
古い情報に起因するパフォーマンスの低下を防ぐためには、継続的なデータの増強が不可欠である。 データストアに新しい関連情報を追加することで、モデルの精度と関連性を維持することができる。
再訓練
新しいデータによるLLMの定期的な再トレーニングは一般的に行われている。 最近のデータでモデルを微調整することで、変化するトレンドに適応し、最新の状態を保つことができる。
アクティブ・ラーニング
アクティブ・ラーニングのテクニックを導入するのもひとつのアプローチだ。 これには、モデルが不確実であったり、エラーを起こしそうなインスタンスを特定し、これらのインスタンスに対するアノテーションを収集することが含まれる。 これらの注釈は、モデルの性能を向上させ、精度を維持するのに役立つ。