هل تساءلت يوما كيف تدير السحابة الخاصة جميع معلوماتها وتتخذ قرارات ذكية؟
هذا هو المكان الذي يتدخل فيه الجيل المعزز للاسترجاع (RAG).
إنها أداة فائقة الذكاء تساعد السحب الخاصة في العثور على المعلومات الصحيحة وإنشاء أشياء مفيدة منها.
تدور هذه المدونة حول كيفية عمل RAG بسحرها في السحب الخاصة ، باستخدام أدوات سهلة وحيل ذكية لجعل كل شيء أكثر سلاسة وأفضل.
الغوص في.
فهم RAG: ما هو؟
الجيل المعزز للاسترجاع (RAG) هو تقنية متطورة تستخدم في معالجة اللغة الطبيعية (NLP) وأنظمة استرجاع المعلومات.
فهو يجمع بين عمليتين أساسيتين: الاسترجاع والتوليد.
استردادفي الفريق الاستشاري للاتصالات الراديوية، تنطوي عملية الاسترجاع على جلب البيانات ذات الصلة من مصادر خارجية مختلفة مثل مستودعات الوثائق أو قواعد البيانات أو السطوح البينية لبرمجة التطبيقات.: يمكن أن تكون هذه البيانات الخارجية متنوعة ، وتشمل معلومات من مصادر وتنسيقات مختلفة.
جيلبمجرد استرجاع البيانات ذات الصلة، تتضمن عملية الإنشاء إنشاء أو إنشاء محتوى أو رؤى أو استجابات جديدة استنادا إلى المعلومات المسترجعة.: يكمل هذا المحتوى الذي تم إنشاؤه البيانات الموجودة ويساعد في صنع القرار أو تقديم استجابات دقيقة.
كيف يعمل الفريق الاستشاري للاتصالات الراديوية؟
الآن ، دعونا نفهم كيف يعمل RAG.
إعداد البيانات
تتضمن الخطوة الأولى تحويل كل من المستندات المخزنة في مجموعة واستعلامات المستخدم إلى تنسيق قابل للمقارنة. هذه الخطوة ضرورية لإجراء عمليات البحث عن التشابه.
التمثيل العددي (التضمينات)
لجعل المستندات واستعلامات المستخدم قابلة للمقارنة لعمليات البحث عن التشابه ، يتم تحويلها إلى تمثيلات رقمية تسمى التضمينات.
يتم إنشاء هذه التضمينات باستخدام نماذج لغة تضمين متطورة وتعمل بشكل أساسي كمتجها رقمي يمثل المفاهيم في النص.
قاعدة بيانات المتجهات
يمكن تخزين تضمينات المستندات ، وهي تمثيلات رقمية للنص ، في قواعد بيانات متجهة مثل Chroma أو Weaviate. تتيح قواعد البيانات هذه التخزين الفعال واسترجاع عمليات التضمين لعمليات البحث عن التشابه.
البحث عن التشابه
استنادا إلى التضمين الذي تم إنشاؤه من استعلام المستخدم ، يتم إجراء بحث عن التشابه في مساحة التضمين. يهدف هذا البحث إلى تحديد نص أو مستندات متشابهة من المجموعة بناء على التشابه العددي لتضمينها.
إضافة السياق
بعد تحديد نص مشابه ، تتم إضافة المحتوى الذي تم استرداده (موجه + نص تم إدخاله) إلى السياق. ثم يتم إدخال هذا السياق المعزز ، الذي يشتمل على كل من الموجه الأصلي والبيانات الخارجية ذات الصلة ، في نموذج اللغة (LLM).
إخراج النموذج
يعالج نموذج اللغة السياق بالبيانات الخارجية ذات الصلة ، مما يمكنه من توليد مخرجات أو استجابات أكثر دقة وذات صلة بالسياق.
5 خطوات لتنفيذ الفريق الاستشاري للاتصالات الراديوية للبيئات السحابية الخاصة
ويرد أدناه دليل شامل بشأن تنفيذ الفريق الاستشاري للاتصالات الراديوية في السحب الخاصة:
1. تقييم جاهزية البنية التحتية
ابدأ بتقييم البنية التحتية السحابية الخاصة الحالية. تقييم قدرات الأجهزة والبرامج والشبكات لضمان التوافق مع تنفيذ الفريق الاستشاري للاتصالات الراديوية. تحديد أي قيود أو متطلبات محتملة للتكامل السلس.
2. جمع البيانات وإعدادها
اجمع البيانات ذات الصلة من مصادر متنوعة داخل بيئة السحابة الخاصة بك. يمكن أن يشمل ذلك مستودعات المستندات وقواعد البيانات وواجهات برمجة التطبيقات ومصادر البيانات الداخلية الأخرى.
تأكد من تنظيم البيانات التي تم جمعها وتنظيفها وإعدادها لمزيد من المعالجة. وينبغي أن تكون البيانات في نسق يمكن إدخاله بسهولة في نظام الفريق الاستشاري للاتصالات الراديوية من أجل عمليات الاسترجاع والتوليد.
3. اختيار نماذج لغة التضمين المناسبة
اختر نماذج لغة التضمين المناسبة التي تتوافق مع متطلبات وحجم بيئة البيئة السحابية الخاصة بك. يمكن اعتبار نماذج مثل BERT أو GPT أو نماذج اللغة المتقدمة الأخرى بناء على مقاييس التوافق والأداء الخاصة بها.
4. تكامل أنظمة التضمين
تنفيذ أنظمة أو أطر قادرة على تحويل المستندات واستعلامات المستخدم إلى تمثيلات رقمية (تضمينات). تأكد من أن هذه التضمينات تلتقط بدقة المعنى الدلالي وسياق البيانات النصية.
قم بإعداد قواعد بيانات المتجهات (على سبيل المثال ، Chroma و Weaviate) لتخزين وإدارة عمليات التضمين هذه بكفاءة ، مما يتيح عمليات البحث عن الاسترجاع والتشابه.
5. الاختبار والتحسين
إجراء اختبارات صارمة للتحقق من وظائف نظام RAG المطبق ودقته وكفاءته داخل بيئة الحوسبة السحابية الخاصة. اختبر سيناريوهات مختلفة لتحديد القيود المحتملة أو مجالات التحسين.
قم بتحسين النظام بناء على نتائج الاختبار والتعليقات أو تحسين الخوارزميات أو ضبط المعلمات أو ترقية مكونات الأجهزة / البرامج حسب الحاجة للحصول على أداء أفضل.
6 أدوات لتنفيذ الفريق الاستشاري للاتصالات الراديوية في السحب الخاصة
فيما يلي نظرة عامة على الأدوات والأطر الأساسية لتنفيذ الجيل المعزز للاسترجاع (RAG) داخل البيئات السحابية الخاصة:
1. تضمين نماذج اللغة
بيرت (تمثيلات التشفير ثنائي الاتجاه من المحولات): BERT هو نموذج لغة قوي مدرب مسبقا مصمم لفهم سياق الكلمات في استعلامات البحث. يمكن ضبطه لمهام استرجاع محددة داخل البيئات السحابية الخاصة.
جي بي تي (محول توليدي مدرب مسبقا): تتفوق نماذج GPT في إنشاء نص يشبه الإنسان بناء على مطالبات معينة. ويمكن أن تكون مفيدة في توليد الاستجابات أو المحتوى في أنظمة الفريق الاستشاري للاتصالات الراديوية.
2. قواعد بيانات المتجهات
صفاءChroma هو محرك بحث متجه محسن للتعامل مع البيانات عالية الأبعاد مثل التضمين.: يقوم بتخزين واسترداد عمليات التضمين بكفاءة ، مما يسهل عمليات البحث السريعة عن التشابه.
نسجWeaviate هو محرك بحث متجه مفتوح المصدر مناسب لإدارة البيانات المتجهة والاستعلام عنها.: وهو يوفر المرونة وقابلية التوسع، وهو مثالي لتطبيقات الفريق الاستشاري للاتصالات الراديوية التي تتعامل مع مجموعات البيانات الكبيرة.
3. أطر لتوليد التضمين
تينسور فلويوفر TensorFlow أدوات وموارد لإنشاء نماذج التعلم الآلي وإدارتها.: يوفر مكتبات لإنشاء عمليات التضمين ودمجها في أنظمة RAG.
بيتورشPyTorch هو إطار عمل شائع آخر للتعلم العميق معروف بمرونته وسهولة استخدامه.: وهو يدعم إنشاء نماذج التضمين ودمجها في تدفقات عمل الفريق الاستشاري للاتصالات الراديوية.
4منصات تكامل RAG
معانقة محولات الوجهتقدم هذه المكتبة مجموعة واسعة من النماذج المدربة مسبقا، بما في ذلك BERT وGPT، مما يسهل دمجها في أنظمة الفريق الاستشاري للاتصالات الراديوية.: يوفر أدوات للتعامل مع عمليات التضمين وتفاعلات نموذج اللغة.
واجهة برمجة تطبيقاتGPT-3 من OpenAIتوفر واجهة برمجة تطبيقات OpenAI الوصول إلى GPT-3 ، مما يتيح للمطورين الاستفادة من قدراتها القوية في توليد اللغة.: ويمكن أن يؤدي دمج GPT-3 في أنظمة الفريق الاستشاري للاتصالات الراديوية إلى تعزيز توليد المحتوى ودقة الاستجابة.
5. الخدمات السحابية
أوس (Amazon Web Services) أو Azure: يقدم موفرو الخدمات السحابية البنية التحتية والخدمات اللازمة لاستضافة تطبيقات RAG وتوسيع نطاقها. إنها توفر موارد مثل الأجهزة الافتراضية والتخزين وقوة الحوسبة المصممة خصيصا لتطبيقات التعلم الآلي.
Google Cloud Platform (GCP): تقدم GCP مجموعة من الأدوات والخدمات للتعلم الآلي الذكاء الاصطناعي ، مما يسمح بنشر وإدارة أنظمة RAG في البيئات السحابية الخاصة.
6. أدوات التطوير المخصصة
مكتبات Python: توفر هذه المكتبات وظائف أساسية لمعالجة البيانات والحسابات العددية وتطوير نموذج التعلم الآلي ، وهو أمر بالغ الأهمية لتنفيذ حلول RAG المخصصة.
واجهات برمجة التطبيقات والبرامج النصية المخصصة: اعتمادا على متطلبات محددة، قد يكون من الضروري تطوير واجهات برمجة التطبيقات والبرامج النصية المخصصة لضبط مكونات الفريق الاستشاري للاتصالات الراديوية ودمجها في البنية التحتية للسحابة الخاصة.
وتؤدي هذه الموارد دورا محوريا في تسهيل التوليد المضمن، وتكامل النماذج، والإدارة الفعالة لأنظمة RAG ضمن إعدادات السحابة الخاصة.
الآن بعد أن عرفت أساسيات RAG للسحابة الخاصة ، حان الوقت لتنفيذها باستخدام الأدوات الفعالة المذكورة أعلاه.
أصبحت القدرة على استرداد البيانات ومعالجتها بكفاءة بمثابة تغيير لقواعد اللعبة في عصر اليوم الذي يعتمد على التكنولوجيا بشكل مكثف. دعونا نستكشف كيف تعيد واجهة برمجة تطبيقات RAG تعريف معالجة البيانات. يجمع هذا النهج المبتكر بين براعة نماذج اللغة الكبيرة (LLMs) والتقنيات القائمة على الاسترجاع لإحداث ثورة في استرجاع البيانات.
ما هي نماذج اللغة الكبيرة (LLMs)؟
النماذج اللغوية الكبيرة (LLMs) هي أنظمة ذكاء اصطناعي متقدمة تعمل كأساس لجيل الاسترجاع المعزز (RAG). LLMs ، مثل GPT (المحولات التوليدية المدربة مسبقا) ، هي نماذج الذكاء الاصطناعي متطورة للغاية وتعتمد على اللغة. لقد تم تدريبهم على مجموعات بيانات واسعة النطاق ويمكنهم فهم وإنشاء نص شبيه بالإنسان ، مما يجعلها لا غنى عنها لمختلف التطبيقات.
وفي سياق واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية، تؤدي هذه المجمعات دورا محوريا في تعزيز استرجاع البيانات ومعالجتها وتوليدها، مما يجعلها أداة متعددة الاستخدامات وقوية لتحسين تفاعلات البيانات.
دعنا نبسط مفهوم واجهة برمجة تطبيقات RAG من أجلك.
ما هو RAG؟
RAG، أو الجيل المعزز للاسترجاع، هو إطار مصمم لتحسين الذكاء الاصطناعي التوليدية. هدفها الأساسي هو التأكد من أن الاستجابات الناتجة عن الذكاء الاصطناعي ليست محدثة وذات صلة بموجه الإدخال فحسب ، بل دقيقة أيضا. ويعد هذا التركيز على الدقة جانبا رئيسيا من وظائف واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية. إنها طريقة رائدة لمعالجة البيانات باستخدام برامج كمبيوتر فائقة الذكاء تسمى نماذج اللغة الكبيرة (LLMs) ، مثل GPT.
تشبه هذه LLMs المعالجات الرقمية التي يمكنها التنبؤ بالكلمات التالية في الجملة من خلال فهم الكلمات التي تسبقها. لقد تعلموا من أطنان من النصوص ، حتى يتمكنوا من الكتابة بطريقة تبدو إنسانية للغاية. باستخدام RAG، يمكنك استخدام هذه المعالجات الرقمية لمساعدتك في العثور على البيانات والعمل معها بطريقة مخصصة. إنه مثل وجود صديق ذكي حقا يعرف كل شيء عن البيانات التي تساعدك!
بشكل أساسي، تقوم RAG بإدخال البيانات المسترجعة باستخدام البحث الدلالي في الاستعلام الذي يتم إجراؤه إلى LLM للرجوع إليها. سنتعمق أكثر في هذه المصطلحات في هذه المقالة.
لمعرفة المزيد عن RAG بعمق، راجع هذه المقالة الشاملة من Cohere
RAG مقابل الضبط الدقيق: ما الفرق بينهما؟
الجانب
واجهة برمجة تطبيقات RAG
الضبط الدقيق
أقبل
يعزز LLMs الموجودة مع السياق من قاعدة البيانات الخاصة بك
متخصص في LLM لمهام محددة
الموارد الحاسوبية
يتطلب موارد حسابية أقل
يتطلب موارد حسابية كبيرة
متطلبات البيانات
مناسب لمجموعات البيانات الأصغر
يتطلب كميات هائلة من البيانات
خصوصية النموذج
نموذج حيادي; يمكن تبديل النماذج حسب الحاجة
نموذج خاص ؛ عادة ما تكون مملة للغاية لتبديل LLMs
القدرة على التكيف مع المجال
حيادي المجال ، متعدد الاستخدامات عبر التطبيقات المختلفة
قد يتطلب التكيف مع مجالات مختلفة
الحد من الهلوسة
يقلل بشكل فعال من الهلوسة
قد تواجه المزيد من الهلوسة دون ضبط دقيق
حالات الاستخدام الشائعة
مثالي لأنظمة الأسئلة والأجوبة (QA) والتطبيقات المختلفة
المهام المتخصصة مثل تحليل المستندات الطبية ، إلخ.
دور قاعدة بيانات المتجهات
تعد قاعدة بيانات المتجهات محورية في الجيل المعزز للاسترجاع (RAG) ونماذج اللغات الكبيرة (LLMs). إنها بمثابة العمود الفقري لتعزيز استرجاع البيانات وزيادة السياق والأداء العام لهذه الأنظمة. فيما يلي استكشاف للدور الرئيسي لقواعد بيانات المتجهات:
التغلب على قيود قاعدة البيانات المنظمة
وغالبا ما تقصر قواعد البيانات التقليدية المنظمة عند استخدامها في واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية نظرا لطبيعتها الجامدة والمحددة مسبقا. إنهم يكافحون من أجل التعامل مع المتطلبات المرنة والديناميكية لتغذية المعلومات السياقية إلى LLMs. تتدخل قواعد بيانات المتجهات لمعالجة هذا القيد.
التخزين الفعال للبيانات في شكل متجه
تتفوق قواعد بيانات المتجهات في تخزين البيانات وإدارتها باستخدام المتجهات الرقمية. يسمح هذا التنسيق بتمثيل البيانات متعدد الاستخدامات ومتعدد الأبعاد. يمكن معالجة هذه المتجهات بكفاءة ، مما يسهل استرجاع البيانات المتقدمة.
ملاءمة البيانات وأدائها
ويمكن لأنظمة الفريق الاستشاري للاتصالات الراديوية النفاذ بسرعة إلى المعلومات السياقية ذات الصلة واسترجاعها من خلال تسخير قواعد بيانات المتجهات. هذا الاسترجاع الفعال أمر بالغ الأهمية لتعزيز سرعة ودقة استجابات توليد LLMs.
التجميع والتحليل متعدد الأبعاد
يمكن للمتجهات تجميع وتحليل نقاط البيانات في مساحة متعددة الأبعاد. وهذه الميزة لا تقدر بثمن بالنسبة للفريق الاستشاري للاتصالات الراديوية، إذ تمكن من تجميع البيانات السياقية وربطها وتقديمها بشكل متماسك إلى LLMs. وهذا يؤدي إلى فهم أفضل وتوليد استجابات مدركة للسياق.
ما هو البحث الدلالي؟
يعد البحث الدلالي حجر الزاوية في واجهة برمجة تطبيقات الجيل المعزز للاسترجاع (RAG) ونماذج اللغات الكبيرة (LLMs). لا يمكن المبالغة في أهميتها ، مما أحدث ثورة في كيفية الوصول إلى المعلومات وفهمها.
ما وراء قاعدة البيانات التقليدية
يتجاوز البحث الدلالي قيود قواعد البيانات المنظمة التي غالبا ما تكافح للتعامل مع متطلبات البيانات الديناميكية والمرنة. بدلا من ذلك ، فإنه يستفيد من قواعد بيانات المتجهات ، مما يسمح بإدارة بيانات أكثر تنوعا وقابلية للتكيف ضرورية لنجاح RAG و LLMs.
تحليل متعدد الأبعاد
واحدة من نقاط القوة الرئيسية للبحث الدلالي هي قدرته على فهم البيانات في شكل متجهات رقمية. يعزز هذا التحليل متعدد الأبعاد فهم علاقات البيانات بناء على السياق ، مما يسمح بإنشاء محتوى أكثر تماسكا ووعيا بالسياق.
استرجاع البيانات بكفاءة
والكفاءة أمر حيوي في استرجاع البيانات، لا سيما لتوليد الاستجابة في الوقت الفعلي في أنظمة واجهة برمجة التطبيقات للفريق الاستشاري للاتصالات الراديوية. يعمل البحث الدلالي على تحسين الوصول إلى البيانات ، مما يحسن بشكل كبير من سرعة ودقة توليد الاستجابات باستخدام LLMs. إنه حل متعدد الاستخدامات يمكن تكييفه مع تطبيقات مختلفة ، من التحليل الطبي إلى الاستعلامات المعقدة مع تقليل عدم الدقة في المحتوى الذي يتم إنشاؤه الذكاء الاصطناعي.
ما المقصود بواجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية؟
اعتبر RAG API بمثابة RAG كخدمة. فهو يجمع كل أساسيات نظام RAG في حزمة واحدة مما يجعل من الملائم استخدام نظام RAG في مؤسستك. تسمح لك RAG API بالتركيز على العناصر الرئيسية لنظام RAG والسماح لواجهة برمجة التطبيقات بالتعامل مع الباقي.
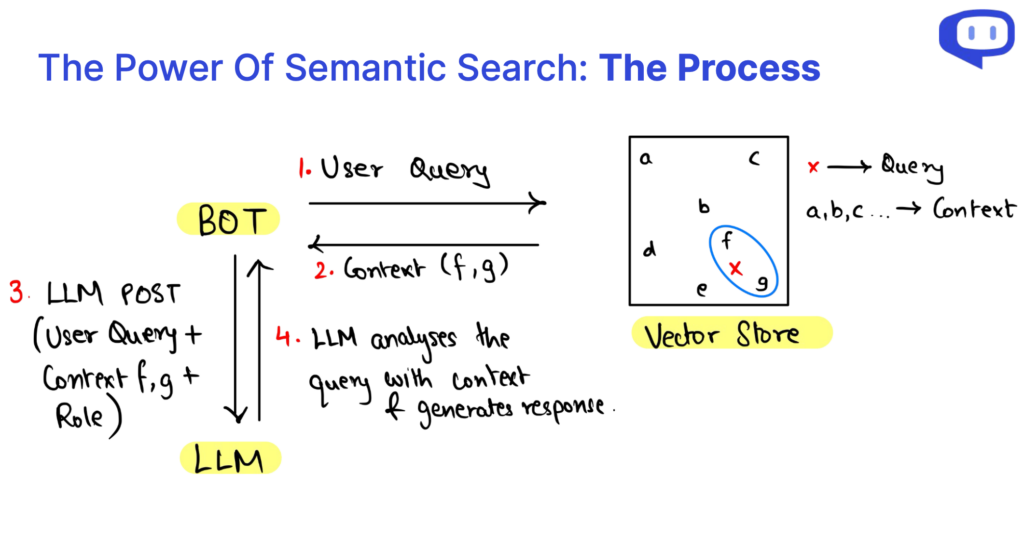
ما هي العناصر ال 3 لاستعلامات واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية؟
عندما نتعمق في تعقيدات الجيل المعزز للاسترجاع (RAG) ، نجد أنه يمكن تشريح استعلام RAG إلى ثلاثة عناصر حاسمة: السياق والدور واستعلام المستخدم. وهذه المكونات هي اللبنات الأساسية التي تشغل نظام الفريق الاستشاري للاتصالات الراديوية، ويؤدي كل منها دورا حيويا في عملية إنشاء المحتوى.
السياق أساس استعلام واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية، حيث يعمل كمستودع للمعارف حيث توجد المعلومات الأساسية. تسمح الاستفادة من البحث الدلالي على بيانات قاعدة المعارف الحالية بسياق ديناميكي ذي صلة باستعلام المستخدم.
الدور الغرض من نظام RAG وتوجيهه لأداء مهام محددة. يوجه النموذج في إنشاء محتوى مصمم خصيصا للمتطلبات ، أو تقديم تفسيرات ، أو الإجابة على الاستفسارات ، أو تلخيص المعلومات.
استعلام المستخدم هو إدخال المستعمل، مما يشير إلى بدء عملية الفريق الاستشاري للاتصالات الراديوية. إنه يمثل تفاعل المستخدم مع النظام وينقل احتياجاته من المعلومات.
وتصبح عملية استرجاع البيانات داخل واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية فعالة من خلال البحث الدلالي. يسمح هذا النهج بتحليل البيانات متعددة الأبعاد ، وتحسين فهمنا لعلاقات البيانات بناء على السياق. وباختصار، فإن استيعاب تشريح استعلامات الفريق الاستشاري للاتصالات الراديوية واسترجاع البيانات عبر البحث الدلالي يمكننا من إطلاق العنان لإمكانات هذه التكنولوجيا، مما يسهل الوصول الفعال إلى المعرفة وتوليد المحتوى الواعي بالسياق.
كيفية تحسين الصلة مع المطالبات؟
تعد الهندسة الفورية أمرا محوريا في توجيه نماذج اللغات الكبيرة (LLMs) داخل RAG لتوليد استجابات ذات صلة بالسياق لمجال معين.
في حين أن قدرة الجيل المعزز للاسترجاع (RAG) على الاستفادة من السياق هي قدرة هائلة ، فإن توفير السياق وحده لا يكفي دائما لضمان استجابات عالية الجودة. هذا هو المكان الذي يتدخل فيه مفهوم المطالبات.
تعمل المطالبة المصممة جيدا كخريطة طريق ل LLM ، وتوجهها نحو الاستجابة المطلوبة. يتضمن عادة العناصر التالية:
إطلاق العنان للصلة السياقية
يعد الجيل المعزز بالاسترجاع (RAG) أداة قوية للاستفادة من السياق. غير أن السياق المجرد قد لا يكون كافيا لضمان استجابات عالية الجودة. هذا هو المكان الذي تكون فيه المطالبات حاسمة في توجيه نماذج اللغات الكبيرة (LLM) داخل RAG لتوليد استجابات تتوافق مع مجالات محددة.
خارطة طريق لبناء دور روبوت لحالة الاستخدام الخاصة بك
تعمل المطالبة جيدة التنظيم كخارطة طريق ، حيث توجه LLMs نحو الاستجابات المطلوبة. يتكون عادة من عناصر مختلفة:
هوية البوت
من خلال ذكر اسم الروبوت ، فإنك تحدد هويته داخل التفاعل ، مما يجعل المحادثة أكثر شخصية.
تعريف المهمة
إن تحديد المهمة أو الوظيفة التي يجب أن تؤديها LLM بوضوح يضمن أنها تلبي احتياجات المستخدم ، سواء كانت توفر المعلومات أو الإجابة على الأسئلة أو أي مهمة محددة أخرى.
مواصفات النغمة
يحدد تحديد النغمة أو أسلوب الاستجابة المطلوب الحالة المزاجية المناسبة للتفاعل ، سواء كانت رسمية أو ودية أو غنية بالمعلومات.
تعليمات متنوعة
يمكن أن تشمل هذه الفئة مجموعة من التوجيهات ، بما في ذلك إضافة روابط وصور أو تقديم تحيات أو جمع بيانات محددة.
صياغة الصلة السياقية
وتمثل صياغة المطالبات بعناية نهجا استراتيجيا لضمان أن يؤدي التآزر بين الفريق الاستشاري للاتصالات الراديوية والماجستير في القانون إلى استجابات مدركة للسياق ووثيقة الصلة بمتطلبات المستعمل، مما يعزز تجربة المستعمل عموما.
لماذا تختار واجهة برمجة تطبيقات RAG الخاصة ب Cody؟
الآن بعد أن اكتشفنا أهمية RAG ومكوناتها الأساسية ، دعنا نقدم Cody كشريك نهائي لجعل RAG حقيقة واقعة. تقدم Cody واجهة برمجة تطبيقات RAG شاملة تجمع بين جميع العناصر الأساسية المطلوبة لاسترجاع البيانات ومعالجتها بكفاءة ، مما يجعلها الخيار الأفضل لرحلة RAG الخاصة بك.
الطراز لا يعرف الطراز
لا داعي للقلق بشأن تبديل النماذج للبقاء على اطلاع بأحدث اتجاهات الذكاء الاصطناعي. باستخدام واجهة برمجة تطبيقات RAG من كودي، يمكنك التبديل بسهولة بين نماذج اللغات الكبيرة أثناء التنقل دون أي تكلفة إضافية.
براعة لا مثيل لها
تعرض واجهة برمجة تطبيقات RAG من Cody تنوعا ملحوظا ، وتتعامل بكفاءة مع تنسيقات الملفات المختلفة وتتعرف على التسلسلات الهرمية النصية لتنظيم البيانات الأمثل.
خوارزمية التقطيع المخصصة
تكمن ميزته البارزة في خوارزميات التقسيم المتقدمة ، مما يتيح تجزئة شاملة للبيانات ، بما في ذلك البيانات الوصفية ، مما يضمن إدارة فائقة للبيانات.
سرعة تفوق المقارنة
يضمن استرجاع البيانات بسرعة البرق على نطاق واسع مع وقت استعلام خطي ، بغض النظر عن عدد الفهارس. يضمن نتائج سريعة لاحتياجات البيانات الخاصة بك.
التكامل والدعم السلس
يوفر Cody تكاملا سلسا مع الأنظمة الأساسية الشائعة والدعم الشامل ، مما يعزز تجربة RAG الخاصة بك ويعزز مكانتها كخيار أفضل لاسترجاع البيانات ومعالجتها بكفاءة. إنه يضمن واجهة مستخدم بديهية لا تتطلب أي خبرة فنية ، مما يجعلها سهلة الوصول وسهلة الاستخدام للأفراد من جميع مستويات المهارة ، مما يزيد من تبسيط تجربة استرجاع البيانات ومعالجتها.
ميزات واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية التي ترتقي بتفاعلات البيانات
في استكشافنا للجيل المعزز للاسترجاع (RAG) ، اكتشفنا حلا متعدد الاستخدامات يدمج نماذج اللغة الكبيرة (LLMs) مع البحث الدلالي وقواعد بيانات المتجهات والمطالبات لتحسين استرجاع البيانات ومعالجتها.
والفريق الاستشاري للاتصالات الراديوية، كونه حياديا للنماذج ومحايدا للمجالات، يحمل وعدا هائلا عبر التطبيقات المتنوعة. ترفع واجهة برمجة تطبيقات RAG من Cody هذا الوعد من خلال تقديم ميزات مثل المعالجة المرنة للملفات ، والتقسيم المتقدم ، والاسترجاع السريع للبيانات ، والتكامل السلس. يستعد هذا المزيج لإحداث ثورة في مشاركة البيانات.
هل أنت مستعد لاحتضان هذا التحول في البيانات؟ أعد تعريف تفاعلات البيانات الخاصة بك واستكشف حقبة جديدة في معالجة البيانات باستخدام Cody الذكاء الاصطناعي.
الأسئلة الشائعة
1. ما الفرق بين RAG ونماذج اللغات الكبيرة (LLMs)؟
تعمل واجهة برمجة تطبيقات RAG (واجهة برمجة تطبيقات التوليد المعززة للاسترجاع) ونماذج اللغات الكبيرة (LLMs) جنبًا إلى جنب.
واجهة برمجة تطبيقات RAG هي واجهة برمجة تطبيقات تجمع بين عنصرين مهمين: آلية استرجاع ونموذج اللغة التوليدي (LLM). والغرض الأساسي منه هو تعزيز استرجاع البيانات وتوليد المحتوى ، مع التركيز بقوة على الاستجابات الواعية بالسياق. غالبا ما يتم تطبيق واجهة برمجة تطبيقات RAG على مهام محددة ، مثل الإجابة على الأسئلة وإنشاء المحتوى وتلخيص النص. إنه مصمم لتقديم ردود ذات صلة بالسياق على استفسارات المستخدم.
من ناحية أخرى ، تشكل LLMs (نماذج اللغة الكبيرة) فئة أوسع من نماذج اللغة مثل GPT (المحولات التوليدية المدربة مسبقا). يتم تدريب هذه النماذج مسبقا على مجموعات بيانات شاملة ، مما يمكنها من إنشاء نص شبيه بالإنسان لمختلف مهام معالجة اللغة الطبيعية. في حين أنها يمكن أن تتعامل مع الاسترجاع والتوليد ، فإن تعدد استخداماتها يمتد إلى تطبيقات مختلفة ، بما في ذلك الترجمة وتحليل المشاعر وتصنيف النص والمزيد.
في جوهرها ، تعد واجهة برمجة تطبيقات RAG أداة متخصصة تجمع بين الاسترجاع والتوليد للاستجابات الواعية بالسياق في تطبيقات محددة. على النقيض من ذلك ، فإن LLMs هي نماذج لغوية أساسية تعمل كأساس لمختلف مهام معالجة اللغة الطبيعية ، وتقدم مجموعة أكثر شمولا من التطبيقات المحتملة التي تتجاوز مجرد الاسترجاع والتوليد.
2. RAG و LLMs – ما هو الأفضل ولماذا؟
يعتمد الاختيار بين RAG API و LLMs على احتياجاتك المحددة وطبيعة المهمة التي تهدف إلى إنجازها. فيما يلي تفصيل للاعتبارات لمساعدتك في تحديد أيهما أفضل لموقفك:
اختر واجهة برمجة تطبيقات RAG إذا:
أنت بحاجة إلى استجابات مدركة للسياق
وتتفوق واجهة برمجة تطبيقات الفريق الاستشاري للاتصالات الراديوية في توفير الاستجابات ذات الصلة بالسياق. إذا كانت مهمتك تتضمن الإجابة على الأسئلة أو تلخيص المحتوى أو إنشاء استجابات خاصة بالسياق، فإن واجهة برمجة تطبيقات RAG هي الخيار المناسب.
لديك حالات استخدام محددة
إذا كان تطبيقك أو خدمتك تحتوي على حالات استخدام محددة جيدا تتطلب محتوى مدركا للسياق، فقد تكون واجهة برمجة تطبيقات RAG مناسبة بشكل أفضل. إنه مصمم خصيصا للتطبيقات حيث يلعب السياق دورا حاسما.
أنت بحاجة إلى تحكم دقيق
تسمح واجهة برمجة تطبيقات RAG بالضبط الدقيق والتخصيص، مما قد يكون مفيدا إذا كانت لديك متطلبات أو قيود محددة لمشروعك.
اختر LLMs إذا:
تحتاج إلى براعة
LLMs ، مثل نماذج GPT ، متعددة الاستخدامات للغاية ويمكنها التعامل مع مجموعة واسعة من مهام معالجة اللغة الطبيعية. إذا كانت احتياجاتك تمتد عبر تطبيقات متعددة ، فإن LLMs توفر المرونة.
تريد بناء حلول مخصصة
يمكنك إنشاء حلول مخصصة لمعالجة اللغة الطبيعية وضبطها لحالة الاستخدام الخاصة بك أو دمجها في مهام سير العمل الحالية.
أنت بحاجة إلى فهم اللغة المدرب مسبقا
تأتي LLMs مدربة مسبقا على مجموعات بيانات واسعة ، مما يعني أن لديهم فهما قويا للغة خارج الصندوق. إذا كنت بحاجة إلى العمل مع كميات كبيرة من البيانات النصية غير المهيكلة ، فيمكن أن تكون LLMs أحد الأصول القيمة.
3. لماذا تحظى LLMs ، مثل نماذج GPT ، بشعبية كبيرة في معالجة اللغة الطبيعية؟
حظيت LLMs باهتمام واسع النطاق بسبب أدائها الاستثنائي عبر المهام اللغوية المختلفة. تُدرَّب أجهزة LLMs على مجموعات بيانات كبيرة. ونتيجة لذلك، يمكنهم فهم وإنتاج نص متماسك وملائم للسياق وصحيح نحويًا من خلال فهم الفروق الدقيقة في أي لغة. بالإضافة إلى ذلك ، فإن إمكانية الوصول إلى LLMs المدربة مسبقا جعلت فهم اللغة الطبيعية وتوليدها مدعوما الذكاء الاصطناعي في متناول جمهور أوسع.
4. ما هي بعض التطبيقات النموذجية ل LLMs؟
يجد LLMs تطبيقات عبر مجموعة واسعة من المهام اللغوية ، بما في ذلك:
فهم اللغة الطبيعية
تتفوق LLMs في مهام مثل تحليل المشاعر والتعرف على الكيانات المسماة والإجابة على الأسئلة. إن قدراتهم القوية على فهم اللغة تجعلها ذات قيمة لاستخراج الرؤى من البيانات النصية.
توليد النص
يمكنهم إنشاء نص شبيه بالإنسان لتطبيقات مثل روبوتات المحادثة وإنشاء المحتوى ، وتقديم استجابات متماسكة وذات صلة بالسياق.
الترجمة الآلية
لقد عززوا بشكل كبير جودة الترجمة الآلية. يمكنهم ترجمة النص بين اللغات بمستوى ملحوظ من الدقة والطلاقة.
تلخيص المحتوى
إنهم بارعون في إنشاء ملخصات موجزة للمستندات أو النصوص المطولة ، مما يوفر طريقة فعالة لاستخلاص المعلومات الأساسية من المحتوى الشامل.
5. كيف يمكن إبقاء LLMs على اطلاع دائم بالبيانات الجديدة والمهام المتطورة؟
ضمان أن تظل LLMs حديثة وفعالة أمر بالغ الأهمية. يتم استخدام العديد من الاستراتيجيات لإبقائها محدثة بالبيانات الجديدة والمهام المتطورة:
زيادة البيانات
تعد الزيادة المستمرة في البيانات أمرا ضروريا لمنع تدهور الأداء الناتج عن المعلومات القديمة. تساعد زيادة مخزن البيانات بمعلومات جديدة ذات صلة النموذج في الحفاظ على دقته وملاءمته.
اعاده
إعادة التدريب الدوري للماجستير مع البيانات الجديدة هي ممارسة شائعة. يضمن ضبط النموذج على البيانات الحديثة أنه يتكيف مع الاتجاهات المتغيرة ويظل محدثا.
التعلم النشط
تنفيذ تقنيات التعلم النشط هو نهج آخر. يتضمن ذلك تحديد الحالات التي يكون فيها النموذج غير مؤكد أو من المحتمل أن يرتكب أخطاء وجمع التعليقات التوضيحية لهذه الحالات. تساعد هذه التعليقات التوضيحية في تحسين أداء النموذج والحفاظ على دقته.