Vous êtes-vous déjà demandé comment les nuages privés gèrent toutes leurs informations et prennent des décisions intelligentes ?
C’est là qu’intervient la génération améliorée par récupération (RAG).
Il s’agit d’un outil super intelligent qui aide les nuages privés à trouver les bonnes informations et à en tirer des éléments utiles.
Ce blog traite de la façon dont RAG opère sa magie dans les nuages privés, en utilisant des outils simples et des astuces astucieuses pour rendre les choses plus fluides et meilleures.
Plongez dans l’aventure.
Comprendre le RAG : qu’est-ce que c’est ?
La génération améliorée pour la recherche (RAG) est une technologie de pointe utilisée dans les systèmes de traitement du langage naturel (NLP) et de recherche d’informations.
Il combine deux processus fondamentaux : la recherche et la génération.
Récupération: Dans le cadre du RAG, le processus de recherche implique la récupération de données pertinentes à partir de diverses sources externes telles que des référentiels de documents, des bases de données ou des API. Ces données externes peuvent être diverses et englober des informations provenant de sources et de formats différents.
Génération: Une fois les données pertinentes récupérées, le processus de génération consiste à créer ou à générer un nouveau contenu, des idées ou des réponses sur la base des informations récupérées. Ce contenu généré complète les données existantes et aide à prendre des décisions ou à fournir des réponses précises.
Comment fonctionne le RAG ?
Comprenons maintenant comment fonctionne le RAG.
Préparation des données
L’étape initiale consiste à convertir les documents stockés dans une collection et les requêtes de l’utilisateur dans un format comparable. Cette étape est cruciale pour effectuer des recherches de similarité.
Représentation numérique (Embeddings)
Afin de rendre les documents et les requêtes des utilisateurs comparables pour les recherches de similarité, ils sont convertis en représentations numériques appelées “embeddings”.
Ces enchâssements sont créés à l’aide de modèles linguistiques d’enchâssement sophistiqués et servent essentiellement de vecteurs numériques représentant les concepts contenus dans le texte.
Base de données vectorielle
Les enchâssements de documents, qui sont des représentations numériques du texte, peuvent être stockés dans des bases de données vectorielles telles que Chroma ou Weaviate. Ces bases de données permettent de stocker et d’extraire de manière efficace les données d’intégration pour les recherches de similarité.
Recherche de similitude
Sur la base de l’intégration générée à partir de la requête de l’utilisateur, une recherche de similarité est effectuée dans l’espace d’intégration. Cette recherche vise à identifier des textes ou des documents similaires dans la collection sur la base de la similarité numérique de leurs encastrements.
Ajout de contexte
Après avoir identifié un texte similaire, le contenu récupéré (invite + texte saisi) est ajouté au contexte. Ce contexte augmenté, comprenant à la fois l’invite originale et les données externes pertinentes, est ensuite introduit dans un modèle linguistique (LLM).
Sortie du modèle
Le modèle linguistique traite le contexte avec des données externes pertinentes, ce qui lui permet de générer des résultats ou des réponses plus précis et plus adaptés au contexte.
5 étapes pour mettre en œuvre le RAG dans les environnements de cloud privé
Vous trouverez ci-dessous un guide complet sur la mise en œuvre de RAG dans les nuages privés :
1. Évaluation de l’état de préparation des infrastructures
Commencez par évaluer l’infrastructure de cloud privé existante. Évaluer le matériel, les logiciels et les capacités du réseau pour s’assurer de leur compatibilité avec la mise en œuvre des RAG. Identifier toute contrainte ou exigence potentielle pour une intégration transparente.
2. Collecte et préparation des données
Rassemblez des données pertinentes provenant de diverses sources au sein de votre environnement de cloud privé. Il peut s’agir de référentiels documentaires, de bases de données, d’API et d’autres sources de données internes.
Veiller à ce que les données collectées soient organisées, nettoyées et préparées en vue d’un traitement ultérieur. Les données doivent être présentées dans un format qui peut être facilement introduit dans le système RAG pour les processus d’extraction et de génération.
3. Sélection de modèles linguistiques d’intégration appropriés
Choisissez des modèles de langage d’intégration appropriés qui correspondent aux exigences et à l’échelle de votre environnement de cloud privé. Des modèles tels que BERT, GPT ou d’autres modèles linguistiques avancés peuvent être envisagés en fonction de leur compatibilité et de leurs performances.
4. Intégration des systèmes d’encastrement
Mettre en œuvre des systèmes ou des cadres capables de convertir des documents et des requêtes d’utilisateurs en représentations numériques (embeddings). Veiller à ce que ces enchâssements capturent avec précision le sens sémantique et le contexte des données textuelles.
Mettre en place des bases de données vectorielles (par exemple, Chroma, Weaviate) pour stocker et gérer efficacement ces encastrements, afin de permettre une récupération rapide et des recherches de similarité.
5. Essais et optimisation
Effectuer des tests rigoureux pour valider la fonctionnalité, la précision et l’efficacité du système RAG mis en œuvre dans l’environnement de cloud privé. Tester différents scénarios pour identifier les limites potentielles ou les domaines à améliorer.
Optimiser le système sur la base des résultats des tests et du retour d’information, en affinant les algorithmes, en réglant les paramètres ou en mettant à niveau les composants matériels/logiciels en fonction des besoins pour améliorer les performances.
6 Outils pour la mise en œuvre de RAG dans les nuages privés
Voici un aperçu des outils et des cadres essentiels à la mise en œuvre de la génération assistée par récupération (RAG) dans les environnements de cloud privé :
1. Intégration de modèles linguistiques
BERT (Bidirectional Encoder Representations from Transformers) : BERT est un puissant modèle linguistique pré-entraîné conçu pour comprendre le contexte des mots dans les requêtes de recherche. Il peut être affiné pour des tâches de recherche spécifiques dans des environnements de nuage privé.
GPT (Generative Pre-trained Transformer) : Les modèles GPT excellent dans la génération de textes de type humain sur la base d’invites données. Ils peuvent contribuer à générer des réponses ou du contenu dans les systèmes RAG.
2. Bases de données vectorielles
Chroma: Chroma est un moteur de recherche vectoriel optimisé pour traiter des données de haute dimension comme les embeddings. Il permet de stocker et de récupérer efficacement les données intégrées, ce qui facilite les recherches rapides de similarités.
Weaviate: Weaviate est un moteur de recherche vectoriel open-source adapté à la gestion et à l’interrogation de données vectorielles. Il offre flexibilité et évolutivité, ce qui est idéal pour les implémentations RAG traitant de grands ensembles de données.
3. Cadres pour la génération d’encastrements
TensorFlow: TensorFlow fournit des outils et des ressources pour créer et gérer des modèles d’apprentissage automatique. Il propose des bibliothèques pour générer des embeddings et les intégrer dans les systèmes RAG.
PyTorch: PyTorch est un autre framework d’apprentissage profond populaire connu pour sa flexibilité et sa facilité d’utilisation. Il permet de créer des modèles d’intégration et de les intégrer dans les flux de travail de RAG.
4. Plateformes d’intégration RAG
Transformateurs à visage embrassant: Cette bibliothèque offre une large gamme de modèles pré-entraînés, y compris BERT et GPT, facilitant leur intégration dans les systèmes RAG. Il fournit des outils pour gérer les interactions entre les modèles linguistiques et les encastrements.
GPT de l’OpenAI–3API: L’API d’OpenAI donne accès à GPT-3, ce qui permet aux développeurs d’utiliser ses puissantes capacités de génération de langage. L’intégration du GPT-3 dans les systèmes RAG peut améliorer la génération de contenu et la précision des réponses.
5. Services en nuage
AWS (Amazon Web Services) ou Azure : Les fournisseurs de services en nuage offrent l’infrastructure et les services nécessaires à l’hébergement et à la mise à l’échelle des implémentations RAG. Ils fournissent des ressources telles que des machines virtuelles, du stockage et de la puissance de calcul adaptées aux applications d’apprentissage automatique.
Google Cloud Platform (GCP) : GCP offre une suite d’outils et de services pour l’apprentissage automatique et l’IA, permettant le déploiement et la gestion des systèmes RAG dans des environnements de cloud privé.
6. Outils de développement personnalisés
Bibliothèques Python: Ces bibliothèques offrent des fonctionnalités essentielles pour la manipulation des données, les calculs numériques et le développement de modèles d’apprentissage automatique, cruciales pour la mise en œuvre de solutions RAG personnalisées.
API personnalisées et Scripts: En fonction des besoins spécifiques, le développement d’API et de scripts personnalisés peut s’avérer nécessaire pour affiner et intégrer les composants RAG dans l’infrastructure du nuage privé.
Ces ressources jouent un rôle essentiel en facilitant la génération d’embedding, l’intégration de modèles et la gestion efficace des systèmes RAG au sein de configurations de clouds privés.
Maintenant que vous connaissez les bases du RAG pour les clouds privés, il est temps de le mettre en œuvre à l’aide des outils efficaces mentionnés ci-dessus.
La capacité à récupérer et à traiter efficacement les données a changé la donne dans l’ère technologique actuelle. Voyons comment l’API RAG redéfinit le traitement des données. Cette approche innovante combine les prouesses des grands modèles de langage (LLM) avec des techniques basées sur la recherche pour révolutionner la recherche de données.
Que sont les grands modèles linguistiques (LLM) ?
Les grands modèles linguistiques (LLM) sont des systèmes d’intelligence artificielle avancés qui servent de base à la génération améliorée par la recherche (RAG). Les LLM, comme le GPT (Generative Pre-trained Transformer), sont des modèles d’IA très sophistiqués, basés sur le langage. Ils ont été formés sur de vastes ensembles de données et peuvent comprendre et générer des textes de type humain, ce qui les rend indispensables pour diverses applications.
Dans le contexte de l’API RAG, ces LLM jouent un rôle central dans l’amélioration de la recherche, du traitement et de la génération de données, ce qui en fait un outil polyvalent et puissant pour optimiser les interactions entre les données.
Simplifions le concept d’API RAG.
Qu’est-ce que le RAG ?
RAG, ou Retrieval-Augmented Generation, est un cadre conçu pour optimiser l’IA générative. Son principal objectif est de garantir que les réponses générées par l’IA sont non seulement à jour et pertinentes par rapport à la demande d’entrée, mais aussi exactes. Ce souci d’exactitude est un aspect essentiel de la fonctionnalité de RAG API. Il s’agit d’un moyen novateur de traiter les données à l’aide de programmes informatiques super intelligents appelés grands modèles de langage (LLM), comme GPT.
Ces LLM sont comme des magiciens numériques capables de prédire les mots qui suivent dans une phrase en comprenant les mots qui les précèdent. Ils ont appris à partir de tonnes de textes, ce qui leur permet d’écrire d’une manière qui semble très humaine. Avec RAG, vous pouvez utiliser ces assistants numériques pour vous aider à trouver et à travailler avec des données de manière personnalisée. C’est comme si un ami très intelligent, qui connaît parfaitement les données, vous aidait !
Essentiellement, RAG injecte des données extraites à l’aide d’une recherche sémantique dans la requête adressée au LLM pour référence. Nous approfondirons ces terminologies dans la suite de l’article.
Pour en savoir plus sur les RAG, consultez cet article détaillé de Cohere.
RAG ou mise au point : Quelle est la différence ?
Aspect
API RAG
Mise au point
Approche
Complète les LLM existants avec le contexte de votre base de données
Spécialisation du LLM pour des tâches spécifiques
Ressources informatiques
Nécessite moins de ressources informatiques
Demande d’importantes ressources informatiques
Exigences en matière de données
Convient aux petits ensembles de données
Nécessite de grandes quantités de données
Spécificité du modèle
Modèle agnostique ; possibilité de changer de modèle en fonction des besoins
Spécifique au modèle ; il est généralement assez fastidieux de changer de LLM.
Adaptabilité du domaine
Indépendant du domaine, polyvalent pour diverses applications
Il peut être nécessaire de l’adapter à différents domaines
Réduction des hallucinations
Réduit efficacement les hallucinations
Risque d’hallucinations plus nombreuses en l’absence d’un réglage minutieux.
Cas d’utilisation courants
Idéal pour les systèmes de questions-réponses (QA), diverses applications
Tâches spécialisées telles que l’analyse de documents médicaux, etc.
Le rôle de la base de données vectorielle
La base de données vectorielle joue un rôle essentiel dans la génération assistée par récupération (RAG) et les grands modèles linguistiques (LLM). Ils constituent l’épine dorsale de l’amélioration de la recherche de données, de l’augmentation du contexte et des performances globales de ces systèmes. Voici une exploration du rôle clé des bases de données vectorielles :
Surmonter les limites des bases de données structurées
Les bases de données structurées traditionnelles sont souvent insuffisantes lorsqu’elles sont utilisées dans le cadre de l’API RAG en raison de leur nature rigide et prédéfinie. Ils ont du mal à gérer les exigences flexibles et dynamiques liées à l’apport d’informations contextuelles aux gestionnaires de l’apprentissage tout au long de la vie. Les bases de données vectorielles permettent de remédier à cette limitation.
Stockage efficace des données sous forme vectorielle
Les bases de données vectorielles permettent de stocker et de gérer des données à l’aide de vecteurs numériques. Ce format permet une représentation polyvalente et multidimensionnelle des données. Ces vecteurs peuvent être traités efficacement, ce qui facilite la recherche avancée de données.
Pertinence et performance des données
Les systèmes RAG peuvent accéder rapidement à des informations contextuelles pertinentes et les récupérer en exploitant des bases de données vectorielles. Cette récupération efficace est cruciale pour améliorer la vitesse et la précision des réponses générées par les mécanismes d’apprentissage tout au long de la vie.
Regroupement et analyse multidimensionnelle
Les vecteurs permettent de regrouper et d’analyser des points de données dans un espace multidimensionnel. Cette fonction est inestimable pour le RAG, car elle permet de regrouper les données contextuelles, de les mettre en relation et de les présenter de manière cohérente aux gestionnaires de l’apprentissage à long terme. Cela permet une meilleure compréhension et la génération de réponses adaptées au contexte.
Qu’est-ce que la recherche sémantique ?
La recherche sémantique est la pierre angulaire de l’API RAG (Retrieval-Augmented Generation) et des grands modèles linguistiques (LLM). On ne saurait trop insister sur son importance, car il a révolutionné la manière dont on accède à l’information et dont on la comprend.
Au-delà des bases de données traditionnelles
La recherche sémantique dépasse les limites des bases de données structurées qui ont souvent du mal à gérer les exigences de données dynamiques et flexibles. Au lieu de cela, il exploite les bases de données vectorielles, ce qui permet une gestion des données plus polyvalente et adaptable, cruciale pour le succès des RAG et des LLM.
Analyse multidimensionnelle
L’un des principaux atouts de la recherche sémantique est sa capacité à comprendre les données sous forme de vecteurs numériques. Cette analyse multidimensionnelle améliore la compréhension des relations entre les données en fonction du contexte, ce qui permet de générer un contenu plus cohérent et mieux adapté au contexte.
Récupération efficace des données
L’efficacité est essentielle dans la récupération des données, en particulier pour la génération de réponses en temps réel dans les systèmes API RAG. La recherche sémantique optimise l’accès aux données, ce qui améliore considérablement la vitesse et la précision de la génération de réponses à l’aide de LLM. Il s’agit d’une solution polyvalente qui peut être adaptée à diverses applications, de l’analyse médicale aux requêtes complexes, tout en réduisant les inexactitudes dans le contenu généré par l’IA.
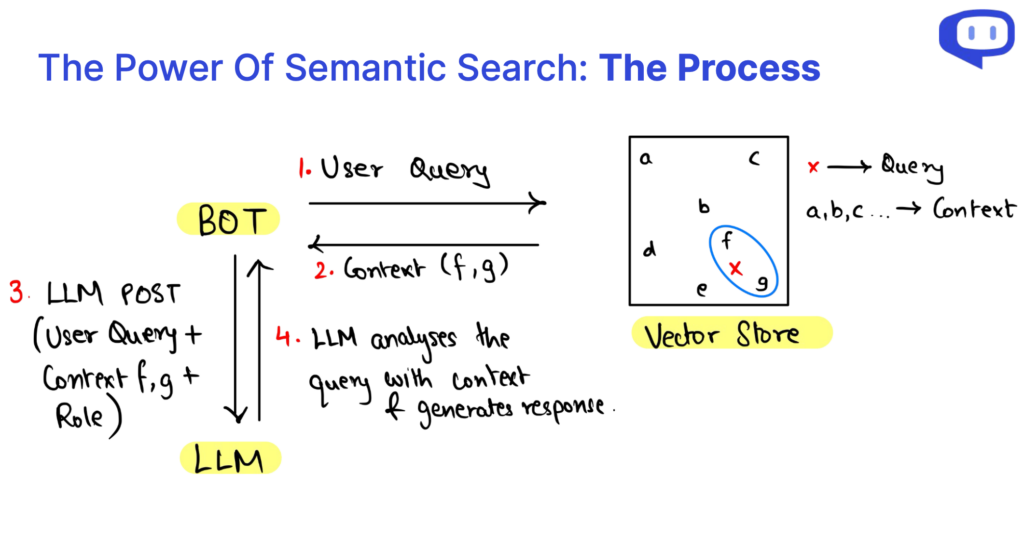
Qu’est-ce que l’API RAG ?
Considérez l’API RAG comme un service RAG. Il rassemble tous les éléments fondamentaux d’un système RAG en un seul paquet, ce qui facilite l’utilisation d’un système RAG au sein de votre organisation. RAG API vous permet de vous concentrer sur les principaux éléments d’un système RAG et de laisser l’API s’occuper du reste.
Quels sont les trois éléments des requêtes API RAG ?
Lorsque nous nous plongeons dans les subtilités de la génération assistée par récupération (RAG), nous constatons qu’une requête RAG peut être disséquée en trois éléments cruciaux : Le contexte, le rôle et la requête de l’utilisateur. Ces composants sont les éléments constitutifs du système RAG, chacun jouant un rôle essentiel dans le processus de génération de contenu.
Le contexte Le contexte constitue la base d’une requête API RAG, servant de référentiel de connaissances où résident les informations essentielles. L’exploitation de la recherche sémantique sur les données de la base de connaissances existante permet d’obtenir un contexte dynamique correspondant à la requête de l’utilisateur.
Le rôle Rôle définit l’objectif du système RAG et l’oriente vers l’exécution de tâches spécifiques. Il guide le modèle dans la génération de contenu adapté aux besoins, en offrant des explications, en répondant à des questions ou en résumant des informations.
La requête de l’utilisateur Requête de l’utilisateur est l’entrée de l’utilisateur, signalant le début du processus RAG. Il représente l’interaction de l’utilisateur avec le système et communique ses besoins d’information.
Le processus de recherche de données au sein de RAG API est rendu efficace par la recherche sémantique. Cette approche permet une analyse multidimensionnelle des données, améliorant ainsi notre compréhension des relations entre les données en fonction du contexte. En bref, comprendre l’anatomie des requêtes RAG et de la recherche de données via la recherche sémantique nous permet de libérer le potentiel de cette technologie, en facilitant l’accès efficace aux connaissances et la génération de contenu tenant compte du contexte.
Comment améliorer la pertinence des messages ?
L’ingénierie des prompts est essentielle pour orienter les grands modèles linguistiques (LLM) au sein de RAG afin de générer des réponses contextuellement pertinentes dans un domaine spécifique.
Bien que la capacité de la génération améliorée par récupération (RAG) à exploiter le contexte soit formidable, fournir le contexte seul n’est pas toujours suffisant pour garantir des réponses de haute qualité. C’est là qu’intervient le concept des messages-guides.
Une invite bien rédigée sert de feuille de route au LLM et l’oriente vers la réponse souhaitée. Il comprend généralement les éléments suivants :
Déverrouiller la pertinence contextuelle
La génération augmentée par récupération (RAG) est un outil puissant qui permet de tirer parti du contexte. Toutefois, le simple contexte peut ne pas suffire à garantir des réponses de qualité. C’est là que les messages-guides jouent un rôle crucial dans l’orientation des grands modèles linguistiques (LLM) au sein de RAG, afin de générer des réponses qui correspondent à des domaines spécifiques.
Feuille de route pour créer un rôle de robot pour votre cas d’utilisation
Une invite bien structurée agit comme une feuille de route, orientant les MFR vers les réponses souhaitées. Il se compose généralement de plusieurs éléments :
Identité du robot
En mentionnant le nom du robot, vous établissez son identité dans l’interaction, ce qui rend la conversation plus personnelle.
Définition des tâches
La définition claire de la tâche ou de la fonction que le MLD doit accomplir garantit qu’il répond aux besoins de l’utilisateur, qu’il s’agisse de fournir des informations, de répondre à des questions ou d’effectuer toute autre tâche spécifique.
Spécification de la tonalité
La spécification du ton ou du style de réponse souhaité crée l’ambiance adéquate pour l’interaction, qu’elle soit formelle, amicale ou informative.
Instructions diverses
Cette catégorie peut englober toute une série de directives, notamment l’ajout de liens et d’images, l’envoi de messages d’accueil ou la collecte de données spécifiques.
Créer une pertinence contextuelle
La formulation réfléchie des questions est une approche stratégique qui permet de garantir que la synergie entre les RAG et les LLM débouche sur des réponses qui tiennent compte du contexte et qui sont très pertinentes par rapport aux exigences de l’utilisateur, ce qui améliore l’expérience globale de l’utilisateur.
Pourquoi choisir l’API RAG de Cody ?
Maintenant que nous avons élucidé l’importance de RAG et de ses principaux éléments, présentons Cody, le partenaire idéal pour faire de RAG une réalité. Cody propose une API RAG complète qui combine tous les éléments essentiels requis pour une récupération et un traitement efficaces des données, ce qui en fait le meilleur choix pour votre parcours RAG.
Agnostique au modèle
Vous n’avez pas à vous soucier de changer de modèle pour rester au fait des dernières tendances en matière d’IA. Grâce à l’API RAG de Cody, vous pouvez facilement passer d’un modèle linguistique à l’autre à la volée, sans frais supplémentaires.
Une polyvalence inégalée
L’API RAG de Cody fait preuve d’une remarquable polyvalence, en gérant efficacement divers formats de fichiers et en reconnaissant les hiérarchies textuelles pour une organisation optimale des données.
Algorithme de regroupement personnalisé
Sa particularité réside dans ses algorithmes de découpage avancés, qui permettent une segmentation complète des données, y compris des métadonnées, garantissant ainsi une gestion supérieure des données.
Une vitesse incomparable
Il garantit une recherche de données ultrarapide à grande échelle avec un temps d’interrogation linéaire, quel que soit le nombre d’index. Il garantit des résultats rapides pour vos besoins en données.
Une intégration et une assistance sans faille
Cody offre une intégration transparente avec les plates-formes les plus courantes et une assistance complète, ce qui améliore votre expérience de RAG et consolide sa position en tant que premier choix pour la récupération et le traitement efficaces des données. Il garantit une interface utilisateur intuitive qui ne nécessite aucune expertise technique, ce qui le rend accessible et convivial pour les personnes de tous niveaux de compétence, rationalisant ainsi davantage l’expérience de recherche et de traitement des données.
Fonctionnalités de l’API RAG qui améliorent les interactions avec les données
Dans notre exploration de la génération assistée par récupération (RAG), nous avons découvert une solution polyvalente qui intègre les grands modèles de langage (LLM) à la recherche sémantique, aux bases de données vectorielles et aux messages-guides afin d’améliorer la récupération et le traitement des données.
Le RAG, qui ne dépend pas d’un modèle ni d’un domaine, est très prometteur pour diverses applications. L’API RAG de Cody permet de tenir cette promesse en offrant des fonctionnalités telles que la gestion flexible des fichiers, le regroupement avancé, la récupération rapide des données et les intégrations transparentes. Cette combinaison est sur le point de révolutionner l’engagement des données.
Êtes-vous prêt à vous engager dans cette transformation des données ? Redéfinissez vos interactions avec les données et entrez dans une nouvelle ère du traitement des données grâce à Cody AI.
FAQ
1. Quelle est la différence entre les RAG et les grands modèles linguistiques (LLM) ?
L’API RAG (Retrieval-Augmented Generation API) et les LLM (Large Language Models) fonctionnent en tandem.
RAG API est une interface de programmation d’applications qui combine deux éléments essentiels : un mécanisme de recherche et un modèle linguistique génératif (LLM). Son objectif principal est d’améliorer la recherche de données et la génération de contenu, en mettant l’accent sur les réponses contextuelles. L’API RAG est souvent appliquée à des tâches spécifiques, telles que la réponse à des questions, la génération de contenu et le résumé de texte. Il est conçu pour apporter des réponses contextuelles pertinentes aux requêtes des utilisateurs.
Les LLM (Large Language Models), quant à eux, constituent une catégorie plus large de modèles linguistiques tels que le GPT (Generative Pre-trained Transformer). Ces modèles sont pré-entraînés sur de vastes ensembles de données, ce qui leur permet de générer des textes de type humain pour diverses tâches de traitement du langage naturel. Bien qu’ils puissent gérer la recherche et la génération, leur polyvalence s’étend à diverses applications, notamment la traduction, l’analyse des sentiments, la classification des textes et bien d’autres encore.
Par essence, RAG API est un outil spécialisé qui combine la recherche et la génération de réponses adaptées au contexte dans des applications spécifiques. Les LLM, en revanche, sont des modèles linguistiques fondamentaux qui servent de base à diverses tâches de traitement du langage naturel, offrant un éventail plus large d’applications potentielles au-delà de la simple recherche et de la génération.
2. RAG et LLM – Qu’est-ce qui est mieux et pourquoi ?
Le choix entre RAG API et LLM dépend de vos besoins spécifiques et de la nature de la tâche que vous souhaitez accomplir. Voici un aperçu des éléments à prendre en compte pour vous aider à déterminer ce qui convient le mieux à votre situation :
Choisir RAG API Si :
Vous avez besoin de réponses adaptées au contexte
RAG API excelle à fournir des réponses contextuelles pertinentes. Si votre tâche consiste à répondre à des questions, à résumer du contenu ou à générer des réponses spécifiques au contexte, l’API RAG est un choix approprié.
Vous avez des cas d’utilisation spécifiques
Si votre application ou votre service a des cas d’utilisation bien définis qui nécessitent un contenu contextuel, l’API RAG peut être mieux adaptée. Il est conçu pour les applications où le contexte joue un rôle crucial.
Vous avez besoin d’un contrôle précis
L’API RAG permet un réglage fin et une personnalisation, ce qui peut être avantageux si vous avez des exigences ou des contraintes spécifiques pour votre projet.
Choisissez les LLM si :
Vous avez besoin de polyvalence
Les LLM, comme les modèles GPT, sont très polyvalents et peuvent traiter un large éventail de tâches de traitement du langage naturel. Si vos besoins concernent plusieurs applications, les LLM offrent une certaine flexibilité.
Vous souhaitez élaborer des solutions personnalisées
Vous pouvez créer des solutions de traitement du langage naturel personnalisées et les adapter à votre cas d’utilisation spécifique ou les intégrer à vos flux de travail existants.
Vous avez besoin d’une compréhension linguistique pré-entraînée
Les LLM sont pré-entraînés sur de vastes ensembles de données, ce qui signifie qu’ils ont une bonne compréhension de la langue dès le départ. Si vous devez travailler avec de grands volumes de données textuelles non structurées, les LLM peuvent être un atout précieux.
3. Pourquoi les LLM, comme les modèles GPT, sont-ils si populaires dans le traitement du langage naturel ?
Les LLM ont fait l’objet d’une grande attention en raison de leurs performances exceptionnelles dans diverses tâches linguistiques. Les LLM sont formés sur de grands ensembles de données. Par conséquent, ils peuvent comprendre et produire des textes cohérents, adaptés au contexte et grammaticalement corrects en comprenant les nuances de n’importe quelle langue. En outre, l’accessibilité des LLM pré-entraînés a rendu la compréhension et la génération de langage naturel par l’IA accessible à un public plus large.
4. Quelles sont les applications typiques des LLM ?
Les LLM trouvent des applications dans un large éventail de tâches linguistiques, notamment :
Compréhension du langage naturel
Les LLM excellent dans des tâches telles que l’analyse des sentiments, la reconnaissance des entités nommées et la réponse aux questions. Leurs solides capacités de compréhension du langage les rendent très utiles pour extraire des informations à partir de données textuelles.
Génération de texte
Ils peuvent générer des textes semblables à ceux des humains pour des applications telles que les chatbots et la génération de contenu, en fournissant des réponses cohérentes et pertinentes en fonction du contexte.
Traduction automatique
Ils ont considérablement amélioré la qualité de la traduction automatique. Ils peuvent traduire des textes d’une langue à l’autre avec une précision et une aisance remarquables.
Résumé du contenu
Ils sont capables de produire des résumés concis de longs documents ou de transcriptions, offrant ainsi un moyen efficace de distiller des informations essentielles à partir d’un contenu étendu.
5. Comment les LLM peuvent-ils être tenus au courant des nouvelles données et de l’évolution des tâches ?
Il est essentiel de veiller à ce que les programmes d’éducation et de formation tout au long de la vie restent d’actualité et efficaces. Plusieurs stratégies sont employées pour les tenir au courant des nouvelles données et de l’évolution des tâches :
Augmentation des données
L’augmentation continue des données est essentielle pour éviter la dégradation des performances due à des informations obsolètes. L’ajout de nouvelles informations pertinentes à la base de données permet au modèle de conserver sa précision et sa pertinence.
Recyclage
Le réentraînement périodique des LLM à l’aide de nouvelles données est une pratique courante. En affinant le modèle sur la base de données récentes, on s’assure qu’il s’adapte à l’évolution des tendances et qu’il reste à jour.
Apprentissage actif
La mise en œuvre de techniques d’apprentissage actif est une autre approche. Il s’agit d’identifier les cas où le modèle est incertain ou susceptible de commettre des erreurs et de collecter des annotations pour ces cas. Ces annotations permettent d’affiner les performances du modèle et de maintenir sa précision.