Haben Sie sich jemals gefragt, wie private Clouds all ihre Informationen verwalten und intelligente Entscheidungen treffen?
An dieser Stelle kommt die Retrieval-Augmented Generation (RAG) ins Spiel.
Es ist ein superschlaues Tool, das privaten Clouds hilft, die richtigen Informationen zu finden und daraus nützliche Dinge zu generieren.
In diesem Blog geht es darum, wie RAG in privaten Clouds mit einfachen Werkzeugen und cleveren Tricks alles reibungsloser und besser macht.
Tauchen Sie ein.
Die RAG verstehen: Was ist das?
Retrieval-Augmented Generation (RAG) ist eine hochmoderne Technologie, die in der Verarbeitung natürlicher Sprache (NLP) und in Information-Retrieval-Systemen eingesetzt wird.
Sie kombiniert zwei grundlegende Prozesse: Abruf und Erzeugung.
Abruf: In RAG umfasst der Abrufprozess das Abrufen relevanter Daten aus verschiedenen externen Quellen wie Dokumentenarchiven, Datenbanken oder APIs. Diese externen Daten können vielfältig sein und Informationen aus verschiedenen Quellen und Formaten umfassen.
Generation: Sobald die relevanten Daten abgerufen sind, umfasst der Generierungsprozess die Erstellung oder Erzeugung neuer Inhalte, Erkenntnisse oder Antworten auf der Grundlage der abgerufenen Informationen. Dieser generierte Inhalt ergänzt die vorhandenen Daten und hilft bei der Entscheidungsfindung oder bei der Bereitstellung genauer Antworten.
Wie funktioniert die RAG?
Nun wollen wir verstehen, wie die RAG funktioniert.
Vorbereitung der Daten
Der erste Schritt besteht darin, sowohl die in einer Sammlung gespeicherten Dokumente als auch die Benutzeranfragen in ein vergleichbares Format zu konvertieren. Dieser Schritt ist entscheidend für die Durchführung von Ähnlichkeitssuchen.
Numerische Darstellung (Einbettungen)
Um Dokumente und Nutzeranfragen für die Ähnlichkeitssuche vergleichbar zu machen, werden sie in numerische Darstellungen, so genannte Embeddings, umgewandelt.
Diese Einbettungen werden mit hochentwickelten Einbettungs-Sprachmodellen erstellt und dienen im Wesentlichen als numerische Vektoren, die die Konzepte im Text darstellen.
Vektor-Datenbank
Die Dokumenteneinbettungen, die numerische Repräsentationen des Textes sind, können in Vektordatenbanken wie Chroma oder Weaviate gespeichert werden. Diese Datenbanken ermöglichen eine effiziente Speicherung und Abfrage von Einbettungen für die Ähnlichkeitssuche.
Ähnlichkeitssuche
Auf der Grundlage der aus der Benutzeranfrage generierten Einbettung wird eine Ähnlichkeitssuche im Einbettungsraum durchgeführt. Diese Suche zielt darauf ab, ähnliche Texte oder Dokumente aus der Sammlung auf der Grundlage der numerischen Ähnlichkeit ihrer Einbettungen zu identifizieren.
Kontext-Zusatz
Nachdem ein ähnlicher Text identifiziert wurde, wird der gefundene Inhalt (Eingabeaufforderung + eingegebener Text) dem Kontext hinzugefügt. Dieser erweiterte Kontext, der sowohl die ursprüngliche Aufforderung als auch die relevanten externen Daten umfasst, wird dann in ein Sprachmodell (LLM) eingespeist.
Ausgabe des Modells
Das Sprachmodell verarbeitet den Kontext mit relevanten externen Daten und kann so genauere und kontextbezogene Ausgaben oder Antworten erzeugen.
5 Schritte zur Implementierung von RAG für private Cloud-Umgebungen
Im Folgenden finden Sie einen umfassenden Leitfaden zur Implementierung von RAG in privaten Clouds:
1. Bewertung der Bereitschaft der Infrastruktur
Beginnen Sie mit der Evaluierung der bestehenden privaten Cloud-Infrastruktur. Bewertung der Hardware-, Software- und Netzwerkkapazitäten, um die Kompatibilität mit der RAG-Implementierung sicherzustellen. Identifizieren Sie alle potenziellen Einschränkungen oder Anforderungen für eine nahtlose Integration.
2. Datenerhebung und -aufbereitung
Sammeln Sie relevante Daten aus verschiedenen Quellen innerhalb Ihrer privaten Cloud-Umgebung. Dazu können Dokumentensammlungen, Datenbanken, APIs und andere interne Datenquellen gehören.
Sicherstellen, dass die gesammelten Daten organisiert, bereinigt und für die weitere Verarbeitung vorbereitet werden. Die Daten sollten in einem Format vorliegen, das leicht in das RAG-System für Abruf- und Generierungsprozesse eingespeist werden kann.
3. Auswahl geeigneter Sprachmodelle für die Einbettung
Wählen Sie geeignete Modelle für die Einbettungssprache, die den Anforderungen und dem Umfang Ihrer privaten Cloud-Umgebung entsprechen. Modelle wie BERT, GPT oder andere fortgeschrittene Sprachmodelle können auf der Grundlage ihrer Kompatibilität und Leistungsmetriken in Betracht gezogen werden.
4. Integration von Einbettsystemen
Implementierung von Systemen oder Rahmenwerken, die in der Lage sind, Dokumente und Benutzeranfragen in numerische Darstellungen (Einbettungen) zu konvertieren. Stellen Sie sicher, dass diese Einbettungen die semantische Bedeutung und den Kontext der Textdaten genau erfassen.
Einrichtung von Vektordatenbanken (z. B. Chroma, Weaviate), um diese Einbettungen effizient zu speichern und zu verwalten, so dass ein schneller Abruf und eine Ähnlichkeitssuche möglich sind.
5. Prüfung und Optimierung
Durchführung strenger Tests zur Validierung der Funktionalität, Genauigkeit und Effizienz des implementierten RAG-Systems innerhalb der privaten Cloud-Umgebung. Testen Sie verschiedene Szenarien, um mögliche Einschränkungen oder verbesserungswürdige Bereiche zu ermitteln.
Optimieren Sie das System auf der Grundlage von Testergebnissen und Rückmeldungen, indem Sie Algorithmen verfeinern, Parameter abstimmen oder Hardware-/Softwarekomponenten bei Bedarf aufrüsten, um die Leistung zu verbessern.
6 Tools für die RAG-Implementierung in Private Clouds
Hier finden Sie einen Überblick über Tools und Frameworks, die für die Implementierung von Retrieval-Augmented Generation (RAG) in privaten Cloud-Umgebungen unerlässlich sind:
1. Einbettung von Sprachmodellen
BERT (Bidirectional Encoder Representations from Transformers): BERT ist ein leistungsstarkes, vorab trainiertes Sprachmodell, das den Kontext von Wörtern in Suchanfragen verstehen soll. Sie kann für spezifische Abrufaufgaben in privaten Cloud-Umgebungen fein abgestimmt werden.
GPT (Generative Pre-trained Transformer): GPT-Modelle zeichnen sich dadurch aus, dass sie auf der Grundlage vorgegebener Aufforderungen menschenähnlichen Text erzeugen. Sie können bei der Erstellung von Antworten oder Inhalten in RAG-Systemen hilfreich sein.
2. Vektorielle Datenbanken
Chroma: Chroma ist eine Vektorsuchmaschine, die für den Umgang mit hochdimensionalen Daten wie Einbettungen optimiert ist. Es speichert und ruft Einbettungen effizient ab und erleichtert eine schnelle Ähnlichkeitssuche.
Weaviate: Weaviate ist eine Open-Source-Vektorsuchmaschine für die Verwaltung und Abfrage von vektorisierten Daten. Es bietet Flexibilität und Skalierbarkeit, ideal für RAG-Implementierungen, die mit großen Datenmengen arbeiten.
3. Rahmen für die Erzeugung von Einbettungen
TensorFlow: TensorFlow bietet Werkzeuge und Ressourcen für die Erstellung und Verwaltung von Machine Learning Modellen. Es bietet Bibliotheken zur Erzeugung von Einbettungen und deren Integration in RAG-Systeme.
PyTorch: PyTorch ist ein weiteres beliebtes Deep-Learning-Framework, das für seine Flexibilität und Benutzerfreundlichkeit bekannt ist. Es unterstützt die Erstellung von Einbettungsmodellen und deren Integration in RAG-Workflows.
4. RAG-Integrationsplattformen
Umarmende Gesichtstransformatoren: Diese Bibliothek bietet eine breite Palette an vortrainierten Modellen, darunter BERT und GPT, die die Integration in RAG-Systeme erleichtern. Es bietet Werkzeuge für die Handhabung von Einbettungen und Sprachmodell-Interaktionen.
OpenAIs GPT–3API: Die API von OpenAI bietet Zugang zu GPT-3 und ermöglicht es Entwicklern, dessen leistungsstarke Sprachgenerierungsfunktionen zu nutzen. Die Integration von GPT-3 in RAG-Systeme kann die Erstellung von Inhalten und die Genauigkeit der Antworten verbessern.
5. Cloud-Dienste
AWS (Amazon Web Services) oder Azure: Cloud-Service-Provider bieten die für das Hosting und die Skalierung von RAG-Implementierungen erforderliche Infrastruktur und Dienste an. Sie stellen Ressourcen wie virtuelle Maschinen, Speicher und Rechenleistung bereit, die auf Anwendungen für maschinelles Lernen zugeschnitten sind.
Google Cloud-Plattform (GCP): GCP bietet eine Reihe von Tools und Diensten für maschinelles Lernen und KI, die die Bereitstellung und Verwaltung von RAG-Systemen in privaten Cloud-Umgebungen ermöglichen.
6. Kundenspezifische Entwicklungswerkzeuge
Python-Bibliotheken: Diese Bibliotheken bieten wesentliche Funktionen für die Datenmanipulation, numerische Berechnungen und die Entwicklung von Modellen für maschinelles Lernen, die für die Implementierung von kundenspezifischen RAG-Lösungen entscheidend sind.
Benutzerdefinierte APIs und Skripte: Je nach den spezifischen Anforderungen kann die Entwicklung von benutzerdefinierten APIs und Skripten erforderlich sein, um die RAG-Komponenten in die Private-Cloud-Infrastruktur zu integrieren und anzupassen.
Diese Ressourcen spielen eine zentrale Rolle bei der Erleichterung der Erzeugung von Einbettungen, der Modellintegration und der effizienten Verwaltung von RAG-Systemen in privaten Cloud-Konfigurationen.
Jetzt, da Sie die Grundlagen von RAG für private Clouds kennen, ist es an der Zeit, sie mit den oben erwähnten effektiven Tools zu implementieren.
Die Fähigkeit, Daten effizient abzurufen und zu verarbeiten, ist im heutigen technologieintensiven Zeitalter ein entscheidender Faktor. Sehen wir uns an, wie die RAG API die Datenverarbeitung neu definiert. Dieser innovative Ansatz kombiniert die Fähigkeiten von Large Language Models (LLMs) mit Retrieval-basierten Techniken, um die Datenabfrage zu revolutionieren.
Was sind große Sprachmodelle (LLMs)?
Large Language Models (LLMs) sind fortschrittliche Systeme der künstlichen Intelligenz, die als Grundlage für die Retrieval-Augmented Generation (RAG) dienen. LLMs, wie der GPT (Generative Pre-trained Transformer), sind hoch entwickelte, sprachgesteuerte KI-Modelle. Sie wurden an umfangreichen Datensätzen trainiert und können menschenähnlichen Text verstehen und generieren, was sie für verschiedene Anwendungen unverzichtbar macht.
Im Kontext der RAG-API spielen diese LLMs eine zentrale Rolle bei der Verbesserung der Datenabfrage, -verarbeitung und -generierung und machen sie zu einem vielseitigen und leistungsstarken Werkzeug zur Optimierung der Dateninteraktion.
Lassen Sie uns das Konzept der RAG API für Sie vereinfachen.
Was ist RAG?
RAG, oder Retrieval-Augmented Generation, ist ein Rahmenwerk zur Optimierung generativer KI. Ihr Hauptziel ist es, sicherzustellen, dass die von der KI generierten Antworten nicht nur aktuell und relevant für die Eingabeaufforderung sind, sondern auch korrekt. Dieser Schwerpunkt auf Genauigkeit ist ein Schlüsselaspekt der Funktionalität von RAG API. Es handelt sich dabei um eine bahnbrechende Methode zur Verarbeitung von Daten mit Hilfe von superintelligenten Computerprogrammen, so genannten Large Language Models (LLMs), wie GPT.
Diese LLMs sind wie digitale Assistenten, die vorhersagen können, welche Wörter als nächstes in einem Satz kommen, indem sie die Wörter vor ihnen verstehen. Sie haben aus Unmengen von Texten gelernt und können daher so schreiben, dass es sehr menschlich klingt. Mit RAG können Sie diese digitalen Assistenten nutzen, um Daten auf individuelle Art und Weise zu finden und zu bearbeiten. Es ist, als hätte man einen wirklich klugen Freund, der alles über Daten weiß und einem hilft!
Im Wesentlichen fügt RAG Daten, die über die semantische Suche abgerufen wurden, in die Anfrage an den LLM als Referenz ein. Wir werden diese Terminologie im weiteren Verlauf des Artikels näher erläutern.
Um mehr über RAG zu erfahren, lesen Sie diesen umfassenden Artikel von Cohere
RAG vs. Feinjustierung: Was ist der Unterschied?
Aspekt
RAG-API
Feinabstimmung
Näherung
Erweitert bestehende LLMs mit Kontext aus Ihrer Datenbank
Spezialisiert LLM für bestimmte Aufgaben
Rechnerische Ressourcen
Benötigt weniger Rechenressourcen
Erfordert erhebliche Rechenressourcen
Anforderungen an die Daten
Geeignet für kleinere Datensätze
Erfordert große Mengen an Daten
Modellspezifität
Modellunabhängig; kann bei Bedarf das Modell wechseln
Modellspezifisch; in der Regel recht mühsam, LLMs zu wechseln
Anpassungsfähigkeit des Bereichs
Bereichsunabhängig, vielseitig für verschiedene Anwendungen
Sie muss möglicherweise für verschiedene Bereiche angepasst werden
Reduktion von Halluzinationen
Reduziert wirksam Halluzinationen
Kann ohne sorgfältige Abstimmung mehr Halluzinationen erleben
Häufige Anwendungsfälle
Ideal für Frage-Antwort-Systeme (QA), verschiedene Anwendungen
Spezialisierte Aufgaben wie die Analyse medizinischer Dokumente usw.
Die Rolle der Vektordatenbank
Die Vektordatenbank ist von zentraler Bedeutung für Retrieval-Augmented Generation (RAG) und Large Language Models (LLMs). Sie dienen als Rückgrat für die Verbesserung der Datenabfrage, der Kontexterweiterung und der Gesamtleistung dieser Systeme. Im Folgenden wird die Schlüsselrolle von Vektordatenbanken untersucht:
Überwindung der Beschränkungen strukturierter Datenbanken
Herkömmliche strukturierte Datenbanken sind aufgrund ihrer starren und vordefinierten Beschaffenheit bei der Verwendung in der RAG API oft unzureichend. Sie haben Schwierigkeiten, die flexiblen und dynamischen Anforderungen an die Bereitstellung von Kontextinformationen für LLM zu erfüllen. Diese Einschränkung wird durch Vektordatenbanken behoben.
Effiziente Speicherung von Daten in Vektorform
Vektordatenbanken zeichnen sich durch die Speicherung und Verwaltung von Daten in Form von numerischen Vektoren aus. Dieses Format ermöglicht eine vielseitige und multidimensionale Datendarstellung. Diese Vektoren können effizient verarbeitet werden, was eine erweiterte Datenabfrage erleichtert.
Datenrelevanz und Leistung
RAG-Systeme können schnell auf relevante Kontextinformationen zugreifen und diese abrufen, indem sie sich Vektordatenbanken zunutze machen. Dieser effiziente Abruf ist von entscheidender Bedeutung für die Verbesserung der Geschwindigkeit und Genauigkeit von LLMs, die Antworten generieren.
Clustering und mehrdimensionale Analyse
Mit Vektoren können Datenpunkte in einem mehrdimensionalen Raum geclustert und analysiert werden. Diese Funktion ist für die RAG von unschätzbarem Wert, da sie es ermöglicht, kontextbezogene Daten zu gruppieren, in Beziehung zu setzen und den LLMs kohärent zu präsentieren. Dies führt zu einem besseren Verständnis und der Generierung kontextbezogener Antworten.
Was ist Semantische Suche?
Die semantische Suche ist ein Eckpfeiler der Retrieval-Augmented Generation (RAG) API und der Large Language Models (LLMs). Ihre Bedeutung kann gar nicht hoch genug eingeschätzt werden, denn sie revolutioniert die Art und Weise, wie Informationen abgerufen und verstanden werden.
Über die traditionelle Datenbank hinaus
Die semantische Suche geht über die Grenzen strukturierter Datenbanken hinaus, die oft nur schwer mit dynamischen und flexiblen Datenanforderungen umgehen können. Stattdessen wird auf Vektordatenbanken zurückgegriffen, was eine vielseitigere und anpassungsfähigere Datenverwaltung ermöglicht, die für den Erfolg der RAG und der LLM entscheidend ist.
Mehrdimensionale Analyse
Eine der größten Stärken der semantischen Suche ist ihre Fähigkeit, Daten in Form von numerischen Vektoren zu verstehen. Diese multidimensionale Analyse verbessert das Verständnis der Datenbeziehungen auf der Grundlage des Kontexts und ermöglicht eine kohärentere und kontextbezogene Inhaltserstellung.
Effizientes Abrufen von Daten
Effizienz ist beim Datenabruf von entscheidender Bedeutung, insbesondere bei der Generierung von Antworten in Echtzeit in RAG-API-Systemen. Die semantische Suche optimiert den Datenzugriff und verbessert die Geschwindigkeit und die Genauigkeit bei der Erstellung von Antworten mit LLMs erheblich. Es handelt sich um eine vielseitige Lösung, die an verschiedene Anwendungen angepasst werden kann, von der medizinischen Analyse bis hin zu komplexen Abfragen, während gleichzeitig Ungenauigkeiten in KI-generierten Inhalten reduziert werden.
Was ist die RAG API?
Betrachten Sie RAG API als RAG-as-a-Service. Es fasst alle Grundlagen eines RAG-Systems in einem Paket zusammen und macht es so einfach, ein RAG-System in Ihrer Organisation einzusetzen. Mit RAG API können Sie sich auf die wichtigsten Elemente eines RAG-Systems konzentrieren und den Rest der API überlassen.
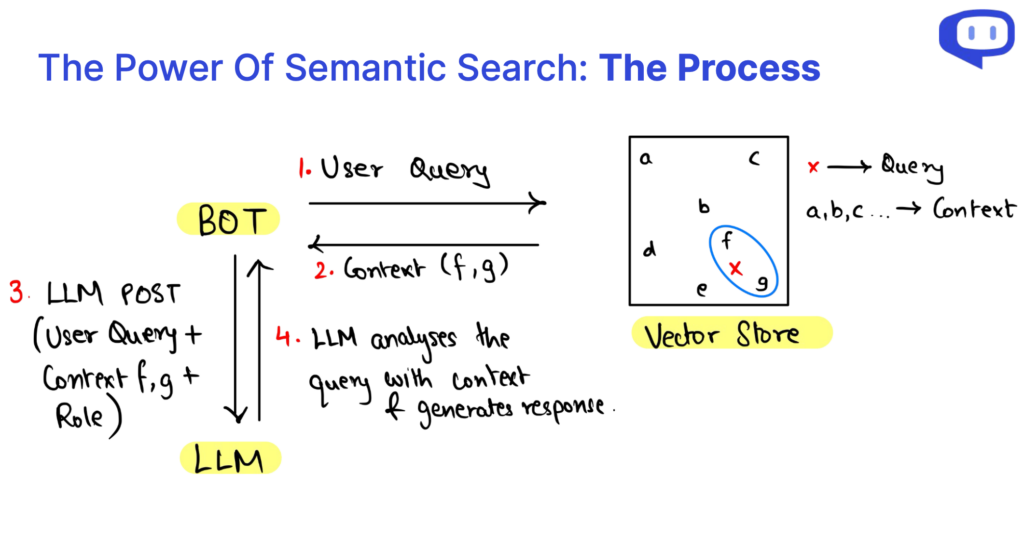
Was sind die 3 Elemente der RAG-API-Abfragen?
Wenn wir in die Feinheiten der Retrieval-Augmented Generation (RAG) eintauchen, stellen wir fest, dass eine RAG-Anfrage in drei entscheidende Elemente zerlegt werden kann: Der Kontext, die Rolle und die Benutzerabfrage. Diese Komponenten sind die Bausteine, die das RAG-System antreiben und die jeweils eine wichtige Rolle im Prozess der Inhaltserstellung spielen.
Die Kontext bildet die Grundlage für eine RAG-API-Abfrage und dient als Wissensspeicher, in dem die wesentlichen Informationen gespeichert sind. Die Nutzung der semantischen Suche auf der bestehenden Wissensdatenbank ermöglicht einen dynamischen Kontext, der für die Benutzeranfrage relevant ist.
Die Rolle definiert den Zweck des RAG-Systems und weist es an, bestimmte Aufgaben zu erfüllen. Es leitet das Modell bei der Erstellung von Inhalten, die auf die Anforderungen zugeschnitten sind, Erklärungen bieten, Anfragen beantworten oder Informationen zusammenfassen.
Die Benutzerabfrage ist die Eingabe des Benutzers, die den Beginn des RAG-Prozesses signalisiert. Sie stellt die Interaktion des Benutzers mit dem System dar und vermittelt seinen Informationsbedarf.
Der Datenabruf innerhalb der RAG API wird durch die semantische Suche effizient gestaltet. Dieser Ansatz ermöglicht eine multidimensionale Datenanalyse und verbessert unser Verständnis der Datenbeziehungen auf der Grundlage des Kontexts. Kurz gesagt, das Verständnis der Anatomie von RAG-Abfragen und der Datenabfrage über die semantische Suche ermöglicht es uns, das Potenzial dieser Technologie zu erschließen und einen effizienten Wissenszugang und eine kontextbezogene Inhaltserstellung zu ermöglichen.
Wie kann man die Relevanz von Prompts verbessern?
Prompt-Engineering ist von zentraler Bedeutung für die Steuerung der Large Language Models (LLMs) innerhalb von RAG, um kontextuell relevante Antworten für einen bestimmten Bereich zu erzeugen.
Die Fähigkeit der Retrieval-Augmented Generation (RAG), Kontext zu nutzen, ist zwar eine beeindruckende Fähigkeit, aber die Bereitstellung von Kontext allein reicht nicht immer aus, um qualitativ hochwertige Antworten zu gewährleisten. An dieser Stelle kommt das Konzept der Prompts ins Spiel.
Ein gut formulierter Prompt dient als Wegweiser für das LLM und lenkt es auf die gewünschte Antwort. Sie umfasst in der Regel die folgenden Elemente:
Entschlüsselung der kontextuellen Relevanz
Retrieval-augmented generation (RAG) ist ein leistungsfähiges Instrument zur Nutzung von Kontext. Der bloße Kontext reicht jedoch möglicherweise nicht aus, um qualitativ hochwertige Antworten zu gewährleisten. Hier sind Prompts von entscheidender Bedeutung, um Large Language Models (LLMs) innerhalb von RAG so zu steuern, dass sie Antworten generieren, die mit bestimmten Domänen übereinstimmen.
Roadmap zur Erstellung einer Bot-Rolle für Ihren Anwendungsfall
Eine gut strukturierte Aufforderung wirkt wie ein Fahrplan, der die LLMs zu den gewünschten Antworten führt. Sie besteht in der Regel aus verschiedenen Elementen:
Bot-Identität
Indem Sie den Namen des Bots erwähnen, stellen Sie seine Identität innerhalb der Interaktion her und machen das Gespräch persönlicher.
Definition der Aufgabe
Durch eine klare Definition der Aufgabe oder Funktion, die LLM erfüllen soll, wird sichergestellt, dass es den Bedürfnissen des Nutzers entspricht, sei es bei der Bereitstellung von Informationen, der Beantwortung von Fragen oder einer anderen spezifischen Aufgabe.
Klangliche Spezifikation
Durch die Angabe des gewünschten Tons oder Stils der Antwort wird die richtige Stimmung für die Interaktion geschaffen, ob formell, freundlich oder informativ.
Verschiedene Anweisungen
Diese Kategorie kann eine Reihe von Anweisungen umfassen, wie z. B. das Hinzufügen von Links und Bildern, das Bereitstellen von Begrüßungen oder das Sammeln bestimmter Daten.
Gestaltung der kontextuellen Relevanz
Eine durchdachte Formulierung der Prompts ist ein strategischer Ansatz, der sicherstellt, dass die Synergie zwischen RAG und LLM zu Antworten führt, die kontextbezogen und in hohem Maße relevant für die Anforderungen des Nutzers sind, was die gesamte Nutzererfahrung verbessert.
Warum Cody’s RAG API wählen?
Nachdem wir nun die Bedeutung der RAG und ihrer Kernkomponenten enträtselt haben, wollen wir Ihnen Cody als den ultimativen Partner für die Verwirklichung der RAG vorstellen. Cody bietet eine umfassende RAG-API, die alle wesentlichen Elemente für eine effiziente Datenabfrage und -verarbeitung vereint und damit die erste Wahl für Ihre RAG-Reise ist.
Modell Agnostiker
Sie müssen sich keine Gedanken über einen Modellwechsel machen, um mit den neuesten KI-Trends Schritt zu halten. Mit der RAG-API von Cody können Sie einfach und ohne zusätzliche Kosten on-the-fly zwischen großen Sprachmodellen wechseln.
Unerreichte Vielseitigkeit
Die RAG-API von Cody zeichnet sich durch eine bemerkenswerte Vielseitigkeit aus, da sie verschiedene Dateiformate effizient verarbeitet und Texthierarchien für eine optimale Datenorganisation erkennt.
Benutzerdefinierter Chunking-Algorithmus
Sein herausragendes Merkmal sind die fortschrittlichen Chunking-Algorithmen, die eine umfassende Datensegmentierung, einschließlich Metadaten, ermöglichen und so eine hervorragende Datenverwaltung gewährleisten.
Unvergleichliche Geschwindigkeit
Sie gewährleistet einen blitzschnellen Datenabruf im großen Maßstab mit einer linearen Abfragezeit, unabhängig von der Anzahl der Indizes. Es garantiert schnelle Ergebnisse für Ihren Datenbedarf.
Nahtlose Integration und Unterstützung
Cody bietet eine nahtlose Integration in gängige Plattformen und einen umfassenden Support, der Ihre RAG-Erfahrung verbessert und seine Position als erste Wahl für effiziente Datenabfrage und -verarbeitung festigt. Sie gewährleistet eine intuitive Benutzeroberfläche, die keinerlei technische Kenntnisse erfordert und somit für Personen aller Qualifikationsstufen zugänglich und benutzerfreundlich ist.
RAG-API-Funktionen zur Verbesserung der Dateninteraktion
Bei der Erforschung von Retrieval-Augmented Generation (RAG) haben wir eine vielseitige Lösung entdeckt, die Large Language Models (LLMs) mit semantischer Suche, Vektordatenbanken und Prompts integriert, um die Datenabfrage und -verarbeitung zu verbessern.
Da RAG modell- und domänenunabhängig ist, ist es vielversprechend für verschiedenste Anwendungen. Die RAG-API von Cody übertrifft dieses Versprechen, indem sie Funktionen wie flexible Dateiverarbeitung, fortschrittliches Chunking, schnellen Datenabruf und nahtlose Integrationen bietet. Diese Kombination ist geeignet, die Datenverwendung zu revolutionieren.
Sind Sie bereit, diese Datenumwandlung in Angriff zu nehmen? Definieren Sie Ihre Dateninteraktionen neu und entdecken Sie eine neue Ära der Datenverarbeitung mit Cody AI.
FAQs
1. Was ist der Unterschied zwischen RAG und großen Sprachmodellen (LLMs)?
RAG API (Retrieval-Augmented Generation API) und LLMs (Large Language Models) arbeiten Hand in Hand.
RAG API ist eine Anwendungsprogrammierschnittstelle, die zwei entscheidende Elemente kombiniert: einen Abrufmechanismus und ein generatives Sprachmodell (LLM). Sein Hauptzweck ist die Verbesserung der Datenabfrage und der Generierung von Inhalten, wobei der Schwerpunkt auf kontextabhängigen Antworten liegt. Die RAG-API wird häufig für bestimmte Aufgaben eingesetzt, z. B. für die Beantwortung von Fragen, die Erstellung von Inhalten und die Zusammenfassung von Texten. Sie ist so konzipiert, dass sie kontextbezogene Antworten auf Benutzeranfragen liefert.
LLMs (Large Language Models) hingegen bilden eine breitere Kategorie von Sprachmodellen wie GPT (Generative Pre-trained Transformer). Diese Modelle werden anhand umfangreicher Datensätze trainiert, so dass sie in der Lage sind, menschenähnlichen Text für verschiedene Aufgaben der natürlichen Sprachverarbeitung zu erzeugen. Sie eignen sich nicht nur für das Abrufen und Generieren von Texten, sondern sind auch vielseitig einsetzbar, z. B. in den Bereichen Übersetzung, Stimmungsanalyse, Textklassifizierung und mehr.
Im Wesentlichen ist die RAG-API ein spezialisiertes Werkzeug, das Abfrage und Generierung für kontextabhängige Antworten in spezifischen Anwendungen kombiniert. LLMs hingegen sind grundlegende Sprachmodelle, die als Basis für verschiedene Aufgaben der natürlichen Sprachverarbeitung dienen und ein breiteres Spektrum an potenziellen Anwendungen bieten, das über die reine Suche und Generierung hinausgeht.
2. RAG und LLMs – Was ist besser und warum?
Die Wahl zwischen RAG API und LLM hängt von Ihren spezifischen Bedürfnissen und der Art der Aufgabe ab, die Sie erfüllen wollen. Im Folgenden finden Sie eine Aufschlüsselung der Überlegungen, die Ihnen dabei helfen sollen, die für Ihre Situation bessere Lösung zu finden:
Wählen Sie RAG API If:
Sie brauchen kontextabhängige Antworten
RAG API zeichnet sich dadurch aus, dass es kontextrelevante Antworten liefert. Wenn Ihre Aufgabe darin besteht, Fragen zu beantworten, Inhalte zusammenzufassen oder kontextspezifische Antworten zu generieren, ist die RAG API eine geeignete Wahl.
Sie haben spezifische Anwendungsfälle
Wenn Ihre Anwendung oder Ihr Dienst klar definierte Anwendungsfälle hat, die kontextabhängige Inhalte erfordern, ist die RAG API möglicherweise besser geeignet. Es wurde speziell für Anwendungen entwickelt, bei denen der Kontext eine entscheidende Rolle spielt.
Sie brauchen eine fein abgestimmte Steuerung
Die RAG API ermöglicht eine Feinabstimmung und Anpassung, was von Vorteil sein kann, wenn Sie spezielle Anforderungen oder Einschränkungen für Ihr Projekt haben.
Wählen Sie LLMs, wenn:
Sie benötigen Vielseitigkeit
LLMs sind ebenso wie GPT-Modelle äußerst vielseitig und können ein breites Spektrum von Aufgaben der natürlichen Sprachverarbeitung bewältigen. Wenn sich Ihr Bedarf auf mehrere Anwendungen erstreckt, bieten LLMs Flexibilität.
Sie möchten maßgeschneiderte Lösungen entwickeln
Sie können benutzerdefinierte Lösungen für die Verarbeitung natürlicher Sprache erstellen und sie für Ihren speziellen Anwendungsfall anpassen oder in Ihre bestehenden Arbeitsabläufe integrieren.
Sie brauchen ein vorgebildetes Sprachverständnis
LLMs werden anhand umfangreicher Datensätze trainiert, was bedeutet, dass sie von Haus aus ein gutes Sprachverständnis haben. Wenn Sie mit großen Mengen an unstrukturierten Textdaten arbeiten müssen, können LLMs eine wertvolle Hilfe sein.
3. Warum sind LLMs, wie GPT-Modelle, so beliebt in der natürlichen Sprachverarbeitung?
LLMs haben aufgrund ihrer außergewöhnlichen Leistungen bei verschiedenen Sprachaufgaben große Aufmerksamkeit erregt. LLMs werden auf großen Datensätzen trainiert. Infolgedessen können sie kohärente, kontextbezogene und grammatikalisch korrekte Texte verstehen und produzieren, indem sie die Nuancen einer jeden Sprache verstehen. Darüber hinaus hat die Zugänglichkeit von vortrainierten LLMs das KI-gestützte Verstehen und Generieren natürlicher Sprache für ein breiteres Publikum zugänglich gemacht.
4. Was sind einige typische Anwendungen von LLMs?
LLMs finden in einem breiten Spektrum von Sprachaufgaben Anwendung, darunter:
Verstehen natürlicher Sprache
LLMs zeichnen sich durch Aufgaben wie Stimmungsanalyse, Erkennung benannter Entitäten und Beantwortung von Fragen aus. Ihre robusten Sprachverstehensfähigkeiten machen sie wertvoll für die Gewinnung von Erkenntnissen aus Textdaten.
Textgenerierung
Sie können menschenähnlichen Text für Anwendungen wie Chatbots und die Erstellung von Inhalten generieren und dabei kohärente und kontextbezogene Antworten liefern.
Maschinelle Übersetzung
Sie haben die Qualität der maschinellen Übersetzung erheblich verbessert. Sie können Texte zwischen Sprachen mit bemerkenswerter Genauigkeit und Geläufigkeit übersetzen.
Zusammenfassung von Inhalten
Sie sind in der Lage, prägnante Zusammenfassungen umfangreicher Dokumente oder Abschriften zu erstellen und bieten so eine effiziente Möglichkeit, aus umfangreichen Inhalten die wesentlichen Informationen zu destillieren.
5. Wie können LLMs mit neuen Daten und sich entwickelnden Aufgaben auf dem Laufenden gehalten werden?
Es ist von entscheidender Bedeutung, dass die LLM aktuell und effektiv bleiben. Es werden mehrere Strategien angewandt, um sie mit neuen Daten und sich entwickelnden Aufgaben auf dem Laufenden zu halten:
Datenerweiterung
Eine kontinuierliche Datenerweiterung ist unerlässlich, um Leistungseinbußen aufgrund veralteter Informationen zu vermeiden. Die Ergänzung des Datenspeichers mit neuen, relevanten Informationen hilft dem Modell, seine Genauigkeit und Relevanz zu erhalten.
Umschulung
Es ist gängige Praxis, LLMs regelmäßig mit neuen Daten neu zu trainieren. Die Feinabstimmung des Modells anhand aktueller Daten stellt sicher, dass es sich an sich ändernde Trends anpasst und auf dem neuesten Stand bleibt.
Aktives Lernen
Ein weiterer Ansatz ist die Anwendung aktiver Lerntechniken. Dies beinhaltet die Identifizierung von Instanzen, in denen das Modell unsicher ist oder wahrscheinlich Fehler macht, und das Sammeln von Kommentaren für diese Instanzen. Diese Anmerkungen tragen dazu bei, die Leistung des Modells zu verbessern und seine Genauigkeit zu erhalten.