
Como começar a usar as ferramentas do Anthropic
O maior benefício de empregar LLMs para tarefas é sua versatilidade. Os LLMs podem ser solicitados de maneiras específicas para atender a uma infinidade de finalidades, funcionando como APIs para geração de texto ou conversão de dados não estruturados em formatos organizados. Muitos de nós recorremos ao ChatGPT para nossas tarefas diárias, seja para escrever e-mails ou para participar de debates divertidos com a IA.
A arquitetura dos plug-ins, também conhecidos como “GPTs”, gira em torno da identificação de palavras-chave de respostas e consultas e da execução de funções relevantes. Esses plug-ins permitem interações com aplicativos externos ou acionam funções personalizadas.
Embora a OpenAI tenha liderado o caminho para permitir chamadas de funções externas para a execução de tarefas, a Anthropic introduziu recentemente um recurso aprimorado chamado “Uso de ferramentas”, substituindo o mecanismo anterior de chamada de funções. Essa versão atualizada simplifica o desenvolvimento ao utilizar JSON em vez de tags XML. Além disso, o Claude-3 Opus apresenta uma vantagem sobre os modelos GPT com sua janela de contexto maior de 200 mil tokens, particularmente valiosa em cenários específicos.
Neste blog, exploraremos o conceito de “Uso de ferramentas”, discutiremos seus recursos e ofereceremos orientações para você começar.
O que é “uso de ferramentas”?
O Claude tem a capacidade de interagir com ferramentas e funções externas do lado do cliente, permitindo que você o equipe com suas próprias ferramentas personalizadas para uma variedade maior de tarefas.
O fluxo de trabalho para usar o Tools com o Claude é o seguinte:
- Fornecer ao Claude ferramentas e um prompt de usuário (solicitação de API)
- Defina um conjunto de ferramentas para o Claude escolher.
- Inclua-os junto com a consulta do usuário no prompt de geração de texto.
- Claude seleciona uma ferramenta
- O Claude analisa o prompt do usuário e o compara com todas as ferramentas disponíveis para selecionar a mais relevante.
- Utilizando o processo de “pensamento” do LLM, ele identifica as palavras-chave necessárias para a ferramenta relevante.
- Geração de respostas (resposta da API)
- Após a conclusão do processo, o prompt de raciocínio, juntamente com a ferramenta e os parâmetros selecionados, é gerado como saída.
Após esse processo, você executa a função/ferramenta selecionada e utiliza sua saída para gerar outra resposta, se necessário.
Esquema geral da ferramenta

Esse esquema serve como um meio de comunicar ao LLM os requisitos do processo de chamada de função. Ele não chama diretamente nenhuma função nem aciona nenhuma ação por conta própria. Para garantir a identificação precisa das ferramentas, você deve fornecer uma descrição detalhada de cada ferramenta. Properties dentro do esquema são utilizados para identificar os parâmetros que serão passados para a função em um estágio posterior.
Demonstração
Vamos criar ferramentas para raspar a Web e encontrar o preço de qualquer ação.
Esquema de ferramentas

Na ferramenta scrape_website, você obterá o URL do site a partir do prompt do usuário. Quanto à ferramenta stock_price, ela identificará o nome da empresa a partir do prompt do usuário e o converterá em um ticker do yfinance.
Prompt do usuário

Ao fazer duas consultas ao bot, uma para cada ferramenta, você obtém os seguintes resultados:

O processo de raciocínio lista todas as etapas realizadas pelo LLM para selecionar com precisão a ferramenta correta para cada consulta e executar as conversões necessárias, conforme descrito nas descrições das ferramentas.
Selecionando a ferramenta relevante
Teremos que escrever algum código adicional que acionará as funções relevantes com base nas condições.

Essa função serve para ativar o código apropriado com base no nome da ferramenta recuperado na resposta do LLM. Na primeira condição, extraímos o URL do site obtido da entrada da ferramenta, enquanto na segunda condição, buscamos o ticker das ações e o passamos para a biblioteca python yfinance.
Execução das funções
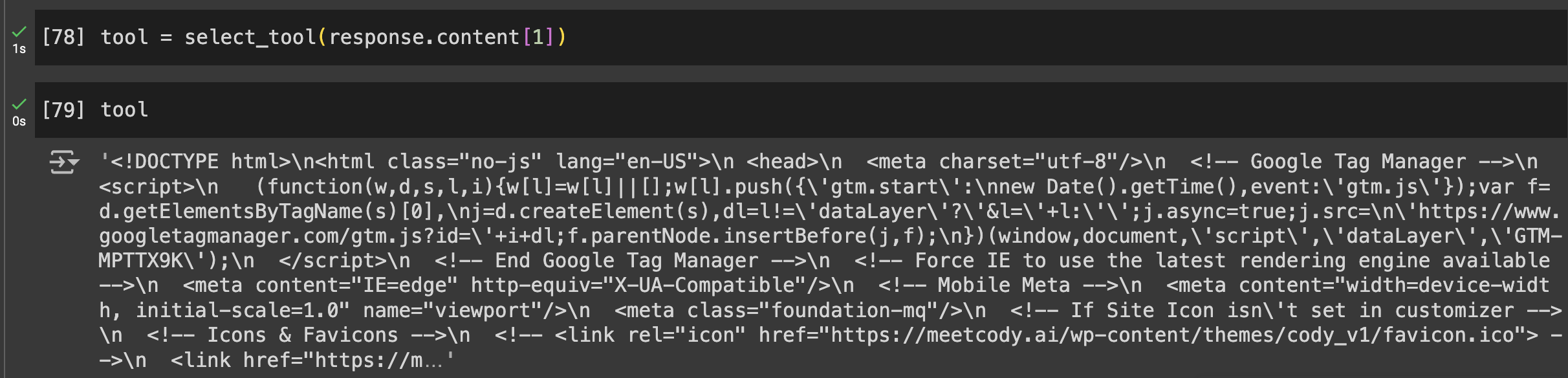
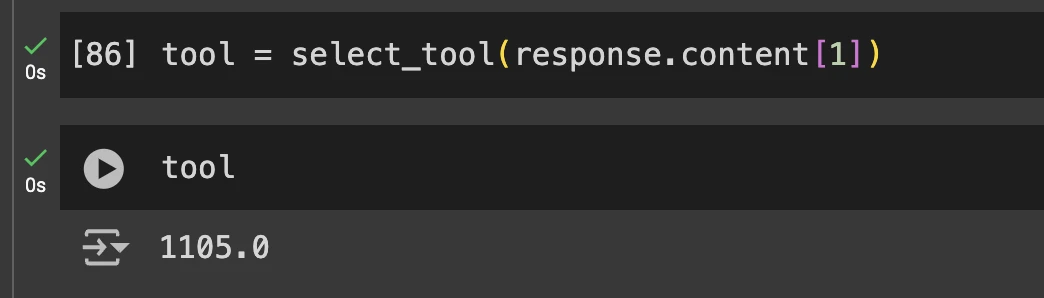
Passaremos o endereço ToolUseBlock inteiro na função select_tool() para acionar o código relevante.
Saídas
- Primeira solicitação
- Segundo prompt

Se quiser ver o código-fonte completo dessa demonstração, você pode ver este notebook.
Alguns casos de uso
O recurso de “uso de ferramentas” para o Claude eleva a versatilidade do LLM a um nível totalmente novo. Embora o exemplo fornecido seja fundamental, ele serve como base para expandir a funcionalidade. Aqui está uma aplicação real disso:
Ontem, a @AnthropicAI lançou uma versão beta para uso da ferramenta!
Aqui está um exemplo de algo que criei com ele: um bot de atendimento ao cliente que pode realmente resolver seu problema!
Estou ansioso para ver o que mais as pessoas construíram! https://t.co/Xmi7pnwouS pic.twitter.com/T5bE4peexR
– Erik Schluntz (@ErikSchluntz) 5 de abril de 2024
Para encontrar mais casos de uso, você pode visitar o repositório oficial do Anthropic
aqui
.






















![Gemma] Criação de um assistente de IA para ciência de dados 🤖](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgg06dhS6iRpIv8hvyonlwncW-RC5n59E8vhaWRgIVqTP-Z1AbTBDtdJsX8ClDILimlGWlRAIORuZn8349TfUFmgqYyCRcoctTvNC_Kv70z41hCKd-0Fy4Ic4EgKyY0LxQ5rDt1eXi3jvEcTxgTC62glTl4e5Cffge50iiF0fxCBqmq9v-u7KTfIL4Lxb0/s1600/Gemma_social.png)