
Rozpoczęcie pracy z narzędziami Anthropic
Największą zaletą zatrudniania LLM do zadań jest ich wszechstronność. LLM mogą być podpowiadane w określony sposób, aby służyć niezliczonym celom, funkcjonując jako API do generowania tekstu lub konwertowania nieustrukturyzowanych danych do zorganizowanych formatów. Wielu z nas korzysta z ChatGPT w codziennych zadaniach, czy to komponując e-maile, czy angażując się w zabawne debaty ze sztuczną inteligencją.
Architektura wtyczek, znanych również jako “GPT”, opiera się na identyfikowaniu słów kluczowych z odpowiedzi i zapytań oraz wykonywaniu odpowiednich funkcji. Wtyczki te umożliwiają interakcję z zewnętrznymi aplikacjami lub uruchamiają niestandardowe funkcje.
Podczas gdy OpenAI przodował w umożliwianiu wywoływania funkcji zewnętrznych do wykonywania zadań, Anthropic wprowadził niedawno ulepszoną funkcję o nazwie “Tool Use”, zastępując poprzedni mechanizm wywoływania funkcji. Zaktualizowana wersja upraszcza programowanie, wykorzystując JSON zamiast znaczników XML. Dodatkowo, Claude-3 Opus może pochwalić się przewagą nad modelami GPT dzięki większemu oknu kontekstowemu wynoszącemu 200 tys. tokenów, co jest szczególnie cenne w określonych scenariuszach.
Na tym blogu zbadamy koncepcję “korzystania z narzędzi”, omówimy jej funkcje i zaoferujemy wskazówki dotyczące rozpoczęcia pracy.
Co to jest “korzystanie z narzędzi”?
Claude ma możliwość interakcji z zewnętrznymi narzędziami i funkcjami po stronie klienta, umożliwiając wyposażenie Claude we własne niestandardowe narzędzia do szerszego zakresu zadań.
Przepływ pracy podczas korzystania z Tools with Claude jest następujący:
- Zapewnienie Claude’owi narzędzi i podpowiedzi dla użytkownika (żądanie API)
- Zdefiniuj zestaw narzędzi do wyboru przez Claude’a.
- Dołącz je wraz z zapytaniem użytkownika do monitu o wygenerowanie tekstu.
- Claude wybiera narzędzie
- Claude analizuje monit użytkownika i porównuje go ze wszystkimi dostępnymi narzędziami, aby wybrać najbardziej odpowiednie.
- Wykorzystując proces “myślenia” LLM, identyfikuje słowa kluczowe wymagane dla odpowiedniego narzędzia.
- Generowanie odpowiedzi (odpowiedź API)
- Po zakończeniu procesu jako dane wyjściowe generowany jest monit wraz z wybranym narzędziem i parametrami.
Po zakończeniu tego procesu użytkownik wykonuje wybraną funkcję/narzędzie i w razie potrzeby wykorzystuje jej dane wyjściowe do wygenerowania kolejnej odpowiedzi.
Ogólny schemat narzędzia

Schemat ten służy jako środek przekazywania wymagań dotyczących procesu wywoływania funkcji do LLM. Nie wywołuje ona bezpośrednio żadnej funkcji ani nie wyzwala samodzielnie żadnych działań. Aby zapewnić dokładną identyfikację narzędzi, należy podać szczegółowy opis każdego z nich. Properties w schemacie są wykorzystywane do identyfikacji parametrów, które zostaną przekazane do funkcji na późniejszym etapie.
Demonstracja
Przejdźmy dalej i zbudujmy narzędzia do skrobania sieci i znajdowania ceny dowolnych akcji.
Narzędzia Schemat

Narzędzie scrape_website pobierze adres URL strony internetowej z monitu użytkownika. Jeśli chodzi o narzędzie stock_price, zidentyfikuje ono nazwę firmy z monitu użytkownika i przekonwertuje ją na ticker yfinance.
Monit użytkownika

Zadanie botowi dwóch zapytań, po jednym dla każdego narzędzia, daje nam następujące wyniki:

Proces myślenia obejmuje wszystkie kroki podejmowane przez LLM w celu dokładnego wyboru odpowiedniego narzędzia dla każdego zapytania i wykonania niezbędnych konwersji zgodnie z opisami narzędzi.
Wybór odpowiedniego narzędzia
Będziemy musieli napisać dodatkowy kod, który uruchomi odpowiednie funkcje w oparciu o warunki.

Funkcja ta służy do aktywacji odpowiedniego kodu na podstawie nazwy narzędzia pobranej w odpowiedzi LLM. W pierwszym warunku pobieramy adres URL strony internetowej uzyskany z danych wejściowych narzędzia, podczas gdy w drugim warunku pobieramy ticker giełdowy i przekazujemy go do biblioteki python yfinance.
Wykonywanie funkcji
Przekażemy cały adres ToolUseBlock w funkcji select_tool(), aby uruchomić odpowiedni kod.
Wyjścia
- Pierwsza zachęta
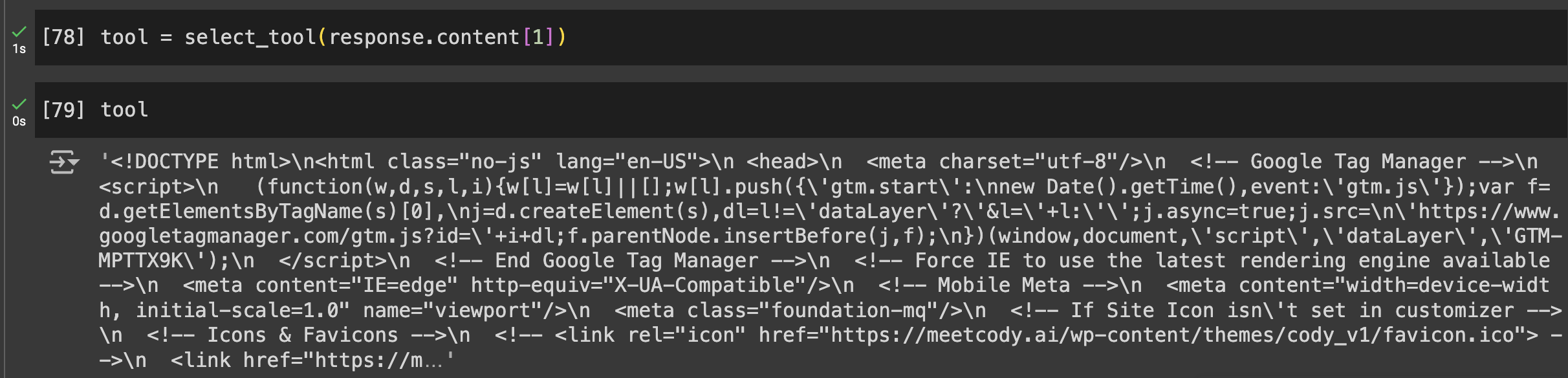
- Druga zachęta
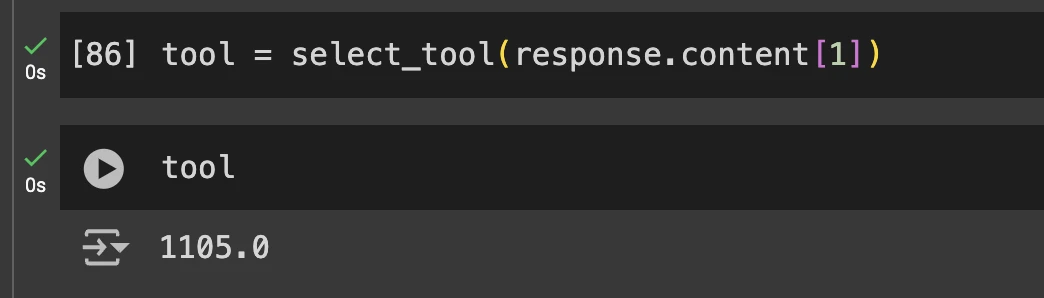

Jeśli chcesz zobaczyć cały kod źródłowy tej demonstracji, możesz wyświetlić ten notatnik.
Niektóre przypadki użycia
Funkcja “tool use” dla Claude podnosi wszechstronność LLM na zupełnie nowy poziom. Chociaż podany przykład jest podstawowy, służy jako podstawa do rozszerzenia funkcjonalności. Oto jedno z jego rzeczywistych zastosowań:
Wczoraj @AnthropicAI uruchomił wersję beta narzędzia!
Oto przykład czegoś, co zbudowałem za jego pomocą: bot obsługi klienta, który może faktycznie rozwiązać twoją sprawę!
Nie mogę się doczekać, aby zobaczyć, co jeszcze ludzie zbudują! https://t.co/Xmi7pnwouS pic.twitter.com/T5bE4peexR
– Erik Schluntz (@ErikSchluntz) 5 kwietnia 2024 r.
Aby znaleźć więcej przypadków użycia, można odwiedzić oficjalne repozytorium Anthropic
tutaj
.






















![Gemma] Building AI Assistant for Data Science 🤖](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgg06dhS6iRpIv8hvyonlwncW-RC5n59E8vhaWRgIVqTP-Z1AbTBDtdJsX8ClDILimlGWlRAIORuZn8349TfUFmgqYyCRcoctTvNC_Kv70z41hCKd-0Fy4Ic4EgKyY0LxQ5rDt1eXi3jvEcTxgTC62glTl4e5Cffge50iiF0fxCBqmq9v-u7KTfIL4Lxb0/s1600/Gemma_social.png)