
OpenAI zaprezentowało swoje najnowsze innowacje AI, modele o1 i o1-Mini, oznaczające znaczący skok w ewolucji sztucznej inteligencji.
Modele te priorytetowo traktują ulepszone rozumowanie i możliwości rozwiązywania problemów, wyznaczając nowy standard w technologii AI.
Ten postęp jest szczególnie godny uwagi ze względu na jego zdolność do radzenia sobie ze złożonymi zadaniami z większą dokładnością i niezawodnością.
Znaczenie i możliwości
Model OpenAI o1, znany z solidnych zdolności rozumowania, prezentuje swoje umiejętności w takich obszarach jak kodowanie i matematyka, przewyższając poprzednie modele, takie jak GPT-4o.
Tymczasem o1-Mini oferuje ekonomiczne rozwiązanie dla aplikacji STEM, wyróżniając się w generowaniu kodu i zadaniach związanych z cyberbezpieczeństwem.
Oba modele zostały zaprojektowane tak, aby “myśleć” przed udzieleniem odpowiedzi, wykorzystując unikalną metodologię “łańcucha myśli”, która naśladuje ludzkie rozumowanie w celu skutecznego rozwiązywania złożonych problemów. 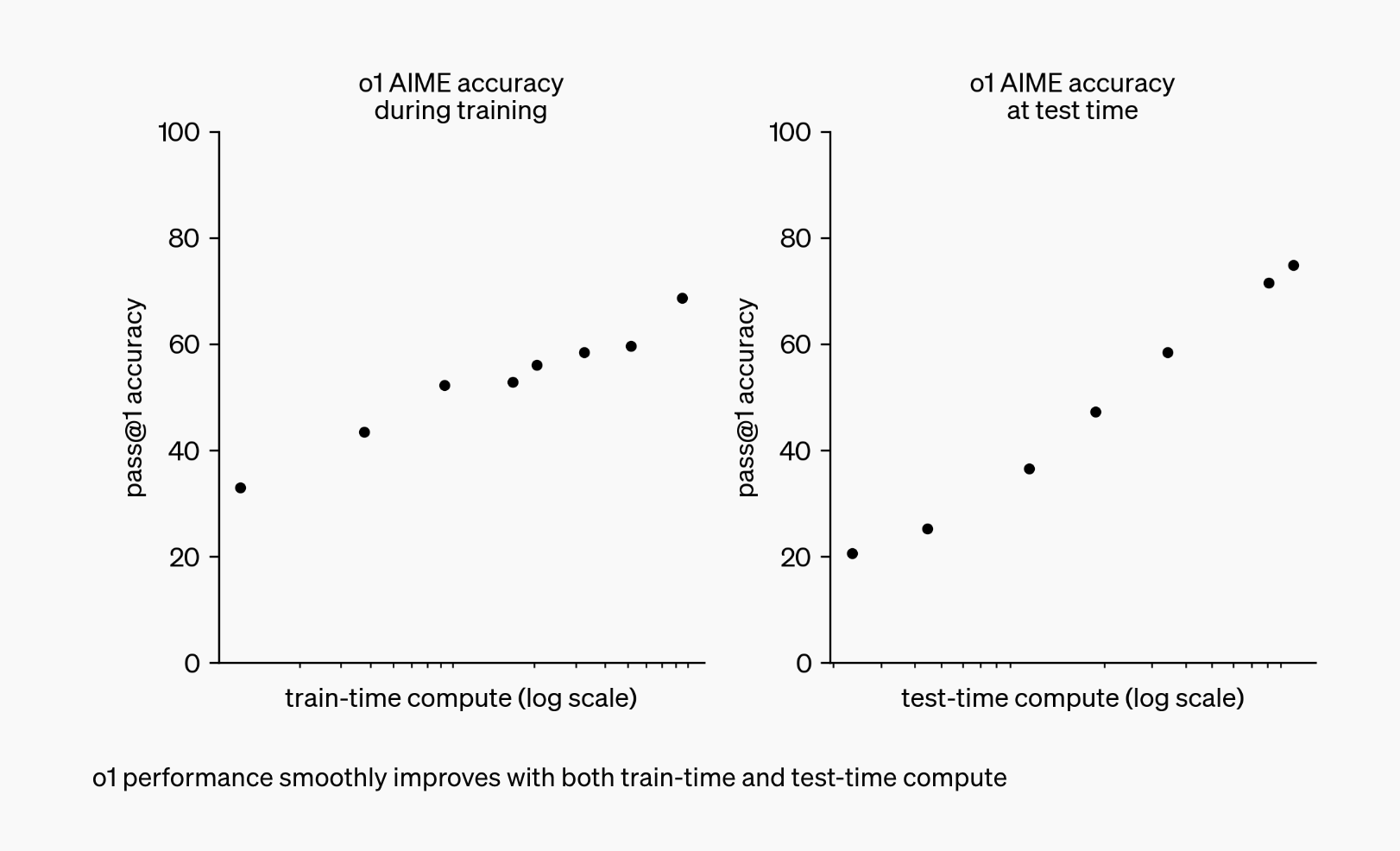
OpenAI o1: Zaawansowane rozumowanie AI
Model OpenAI o1 jest przełomowym osiągnięciem w dziedzinie sztucznej inteligencji, kładącym nacisk na zwiększone możliwości rozumowania.
Model ten wyróżnia się zdolnością do rozwiązywania złożonych problemów przy użyciu innowacyjnego podejścia.
Model o1 wykorzystuje zaawansowane techniki szkoleniowe, takie jak uczenie ze wzmocnieniem, które pozwala mu uczyć się na własnych sukcesach i błędach, oraz metodologię “Chain of Thought”, która dzieli skomplikowane pytania na łatwe do opanowania kroki, podobne do ludzkich procesów poznawczych.
Wydajność o1 w dziedzinach takich jak matematyka i kodowanie jest szczególnie imponująca, przewyższając swoich poprzedników poprzez rozwiązywanie złożonych problemów z większą dokładnością i szybkością.
Zademonstrował doskonałe wyniki w konkurencyjnych konkursach programistycznych i matematycznych, w tym w Międzynarodowej Olimpiadzie Matematycznej, pokazując swoje umiejętności w tych dziedzinach.
Model ten wyznacza nowy punkt odniesienia dla możliwości sztucznej inteligencji, wskazując na znaczący krok w kierunku osiągnięcia rozumowania podobnego do ludzkiego w sztucznej inteligencji.
OpenAI o1-Mini: Ekonomiczna doskonałość AI
Jako niedroga alternatywa, model o1-Mini firmy OpenAI oferuje imponujące połączenie opłacalności i solidnych możliwości rozumowania.
Dostosowany specjalnie do zastosowań STEM, o1-Mini wyróżnia się w takich obszarach jak matematyka, kodowanie i cyberbezpieczeństwo.
Osiągnął niezwykłe wyniki w testach porównawczych, takich jak Codeforces i cyberbezpieczeństwo CTF, demonstrując swoją biegłość w zadaniach technicznych.
W porównaniu do swojego odpowiednika, o1, model o1-Mini został zaprojektowany tak, aby był bardziej opłacalny przy zachowaniu godnych pochwały poziomów wydajności.
Choć może nie dorównywać wszechstronnym możliwościom o1 w zakresie rozumowania, oferuje praktyczne rozwiązanie dla aplikacji wymagających szybkiego i wydajnego rozwiązywania problemów przy niższych kosztach.
Dodatkowo, szybkość o1-Mini jest zaletą, dzięki czemu nadaje się do scenariuszy, w których szybkie reakcje są niezbędne, zapewniając w ten sposób wszechstronne narzędzie w krajobrazie sztucznej inteligencji.
Ceny i dostępność OpenAI o1 i o1-Mini

Strategiczna polityka cenowa OpenAI dla modeli o1 i o1-Mini odzwierciedla zaangażowanie firmy w uczynienie zaawansowanej sztucznej inteligencji dostępną i opłacalną.
Strategia cenowa OpenAI o1 została zaprojektowana z myślą o sektorach, w których rozwiązywanie złożonych problemów ma kluczowe znaczenie, takich jak badania naukowe i zaawansowane zadania kodowania.
Z kolei o1-Mini oferuje bardziej przystępną cenowo opcję, zapewniając doskonałą wydajność w aplikacjach STEM bez wyższych kosztów.  W porównaniu do swoich poprzedników, oba modele charakteryzują się lepszą opłacalnością.
W porównaniu do swoich poprzedników, oba modele charakteryzują się lepszą opłacalnością.
Podczas gdy o1 jest bardziej znaczącą inwestycją, jego dokładność i wydajność w złożonych zadaniach rozumowania uzasadniają ten wydatek.
Tymczasem przystępna cena o1-Mini sprawia, że jest on odpowiedni dla edukacji, startupów i małych firm, które potrzebują niezawodnych rozwiązań AI bez ponoszenia wysokich kosztów.
Strategia cenowa OpenAI zapewnia, że modele te są dostępne w różnych sektorach, promując szersze zastosowanie i innowacje.
Podsumowanie: Przyszłość sztucznej inteligencji z OpenAI
Wprowadzenie modeli o1 i o1-Mini firmy OpenAI oznacza znaczący postęp w technologii sztucznej inteligencji, zwłaszcza w zakresie zdolności rozumowania i rozwiązywania problemów.
Modele te mają zrewolucjonizować dziedziny wymagające złożonych zadań poznawczych, oferując bezprecedensową dokładność i wydajność.
Z o1 wiodącym w skomplikowanych obszarach, takich jak kodowanie i matematyka, oraz o1-Mini zapewniającym opłacalne rozwiązania dla aplikacji STEM, OpenAI toruje drogę dla bardziej dostępnych innowacji AI.
Patrząc w przyszłość, ciągły nacisk OpenAI na udoskonalanie zdolności rozumowania tych modeli sugeruje świetlaną przyszłość dla roli AI w różnych branżach.
W miarę jak OpenAI będzie dalej ulepszać te modele, ich potencjał do naśladowania ludzkiego rozumowania wzrośnie, obiecując transformacyjny wpływ na badania naukowe, edukację i nie tylko.
Ostatecznie, o1 i o1-Mini reprezentują nową erę rozwoju sztucznej inteligencji, która może na nowo zdefiniować sposób, w jaki technologia pomaga w rozwiązywaniu rzeczywistych wyzwań.







