
OpenAI a dévoilé ses dernières innovations en matière d’intelligence artificielle, les modèles o1 et o1-Mini, qui marquent une étape importante dans l’évolution de l’intelligence artificielle.
Ces modèles mettent l’accent sur l’amélioration des capacités de raisonnement et de résolution de problèmes, établissant ainsi une nouvelle norme dans la technologie de l’IA.
Cette avancée est particulièrement remarquable pour sa capacité à s’attaquer à des tâches complexes avec une précision et une fiabilité accrues.
Importance et capacités
Le modèle OpenAI o1, connu pour ses solides capacités de raisonnement, démontre ses prouesses dans des domaines tels que le codage et les mathématiques, surpassant les modèles précédents tels que le GPT-4o.
Le modèle o1-Mini offre quant à lui une solution rentable pour les applications STEM, excellant dans la génération de code et les tâches de cybersécurité.
Les deux modèles sont conçus pour “penser” avant de répondre, en utilisant une méthodologie unique de “chaîne de pensée” qui imite le raisonnement humain pour résoudre efficacement des problèmes complexes. 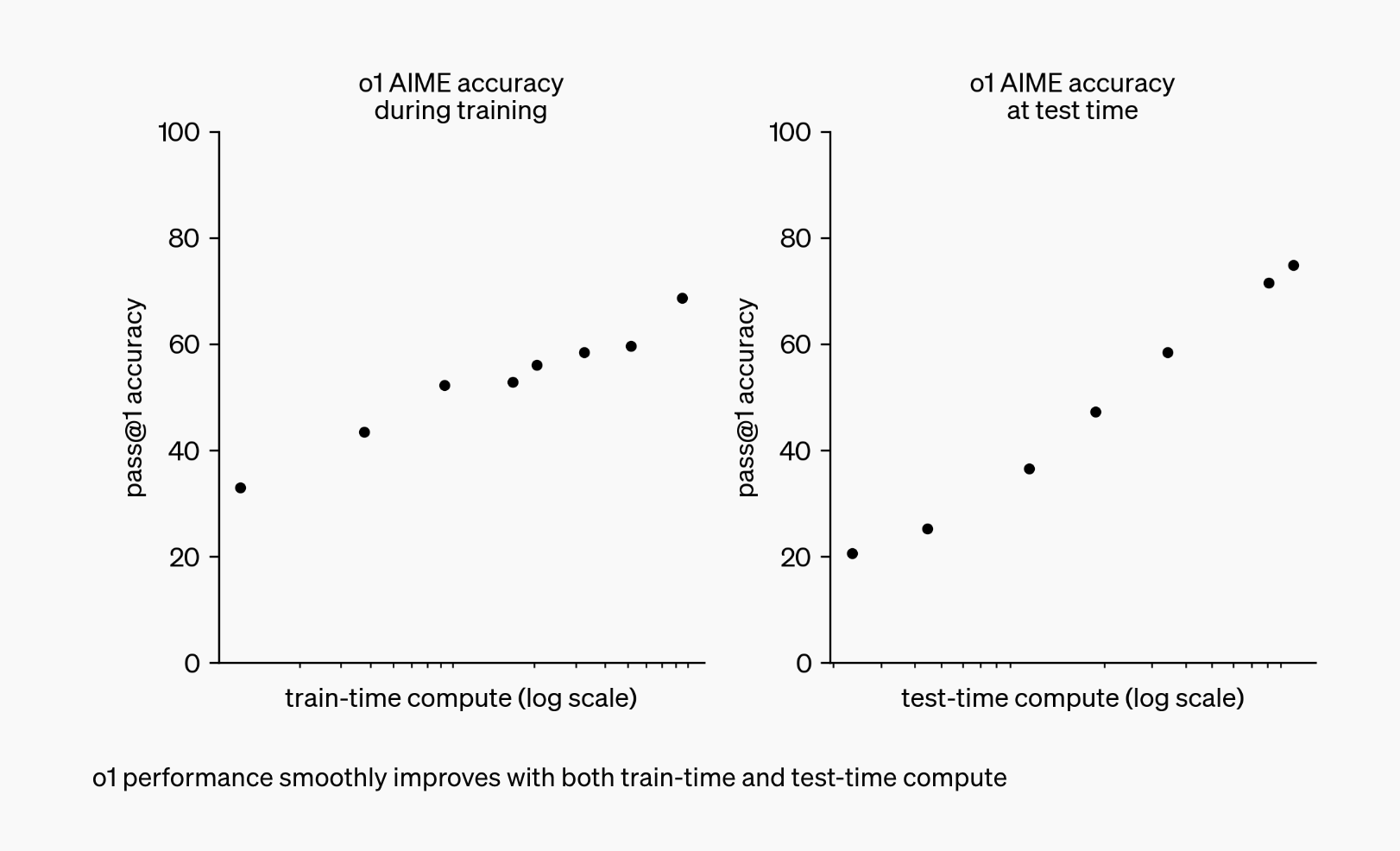
OpenAI o1 : Faire progresser le raisonnement en IA
Le modèle OpenAI o1 est un développement révolutionnaire dans le domaine de l’IA, qui met l’accent sur des capacités de raisonnement améliorées.
Ce modèle se distingue par sa capacité à aborder des problèmes complexes avec une approche innovante.
Le modèle o1 utilise des techniques de formation avancées telles que l’apprentissage par renforcement, qui lui permet d’apprendre de ses succès et de ses erreurs, et la méthodologie de la “chaîne de pensée”, qui décompose les questions complexes en étapes gérables, à l’instar des processus cognitifs humains.
Les performances d’o1 dans des domaines tels que les mathématiques et le codage sont particulièrement impressionnantes : il surpasse ses prédécesseurs en résolvant des problèmes complexes avec plus de précision et de rapidité.
Il a obtenu des résultats supérieurs lors de concours de programmation et de mathématiques, notamment lors de l’Olympiade internationale de mathématiques, démontrant ainsi ses prouesses dans ces domaines.
Ce modèle établit une nouvelle référence en matière de capacités d’intelligence artificielle, ce qui représente une avancée significative vers l’obtention d’un raisonnement semblable à celui de l’homme dans le domaine de l’intelligence artificielle.
OpenAI o1-Mini : L’excellence de l’IA à moindre coût
En tant qu’alternative économique, le modèle o1-Mini d’OpenAI offre un mélange impressionnant de rentabilité et de capacités de raisonnement robustes.
Conçu spécifiquement pour les applications STEM, o1-Mini excelle dans des domaines tels que les mathématiques, le codage et la cybersécurité.
Il a obtenu des scores remarquables dans des tests de référence tels que Codeforces et les CTF de cybersécurité, démontrant ainsi sa compétence dans les tâches techniques.
Comparé à son homologue, o1, le modèle o1-Mini est conçu pour être plus rentable tout en conservant des niveaux de performance louables.
Bien qu’il n’atteigne pas les capacités complètes de o1 en termes de raisonnement, il offre une solution pratique pour les applications nécessitant une résolution rapide et efficace des problèmes à moindre coût.
En outre, la vitesse de o1-Mini est un avantage qui le rend adapté aux scénarios dans lesquels des réponses rapides sont essentielles, fournissant ainsi un outil polyvalent dans le paysage de l’IA.
Prix et accessibilité de l’OpenAI o1 et o1-Mini

La tarification stratégique d’OpenAI pour les modèles o1 et o1-Mini reflète son engagement à rendre l’IA avancée accessible et rentable.
La stratégie de prix de l’OpenAI o1 est conçue pour répondre aux besoins des secteurs où la résolution de problèmes complexes est essentielle, tels que la recherche scientifique et les tâches de codage avancées.
En revanche, o1-Mini offre une option plus abordable, offrant d’excellentes performances dans les applications STEM sans pour autant être plus onéreux.  Par rapport à leurs prédécesseurs, les deux modèles présentent un meilleur rapport coût-efficacité.
Par rapport à leurs prédécesseurs, les deux modèles présentent un meilleur rapport coût-efficacité.
Bien que l’o1 représente un investissement plus important, sa précision et son efficacité dans les tâches de raisonnement complexes justifient la dépense.
Quant à l’o1-Mini, son prix abordable le rend adapté à l’éducation, aux startups et aux petites entreprises qui ont besoin de solutions d’IA fiables sans avoir à supporter des coûts élevés.
La stratégie de prix d’OpenAI garantit que ces modèles sont accessibles dans différents secteurs, ce qui favorise une adoption plus large et l’innovation.
Conclusion : L’avenir de l’IA avec OpenAI
L’introduction des modèles o1 et o1-Mini d’OpenAI marque une avancée significative dans la technologie de l’IA, en particulier dans les capacités de raisonnement et de résolution de problèmes.
Ces modèles devraient révolutionner les domaines nécessitant des tâches cognitives complexes, en offrant une précision et une efficacité sans précédent.
Avec o1 en tête dans des domaines complexes tels que le codage et les mathématiques, et o1-Mini fournissant des solutions rentables pour les applications STEM, OpenAI ouvre la voie à des innovations plus accessibles en matière d’IA.
L’accent mis par OpenAI sur le perfectionnement des capacités de raisonnement de ces modèles laisse entrevoir un avenir radieux pour le rôle de l’IA dans tous les secteurs d’activité.
Au fur et à mesure que l’OpenAI améliore ces modèles, leur potentiel d’émulation du raisonnement humain augmente, ce qui promet des impacts transformateurs dans la recherche scientifique, l’éducation et au-delà.
En fin de compte, o1 et o1-Mini représentent une nouvelle ère de développement de l’IA, prête à redéfinir la façon dont la technologie aide à résoudre les défis du monde réel.







