
Cómo empezar a utilizar las Herramientas Antrópicas
La mayor ventaja de emplear LLM para tareas es su versatilidad. Los LLM pueden impulsarse de formas específicas para servir a un sinfín de propósitos, funcionando como API para la generación de texto o convirtiendo datos no estructurados en formatos organizados. Muchos de nosotros recurrimos a ChatGPT para nuestras tareas diarias, ya sea redactar correos electrónicos o participar en debates lúdicos con la IA.
La arquitectura de los plugins, también conocidos como “GPT”, gira en torno a la identificación de palabras clave a partir de respuestas y consultas y la ejecución de las funciones pertinentes. Estos plugins permiten interactuar con aplicaciones externas o activar funciones personalizadas.
Mientras que OpenAI fue pionera en permitir llamadas a funciones externas para la ejecución de tareas, Anthropic ha introducido recientemente una función mejorada llamada “Uso de herramientas”, que sustituye a su anterior mecanismo de llamada a funciones. Esta versión actualizada simplifica el desarrollo utilizando JSON en lugar de etiquetas XML. Además, Claude-3 Opus tiene una ventaja sobre los modelos GPT con su mayor ventana de contexto de 200.000 fichas, especialmente valiosa en escenarios específicos.
En este blog, exploraremos el concepto de “Uso de herramientas”, discutiremos sus características y ofreceremos orientación para empezar.
¿Qué es el “uso de herramientas”?
Claude tiene capacidad para interactuar con herramientas y funciones externas del lado del cliente, lo que te permite equipar a Claude con tus propias herramientas personalizadas para una gama más amplia de tareas.
El flujo de trabajo para utilizar Herramientas con Claude es el siguiente:
- Proporcionar a Claude herramientas y una solicitud de usuario (solicitud API)
- Define un conjunto de herramientas para que Claude pueda elegir.
- Inclúyelos junto con la consulta del usuario en la consulta de generación de texto.
- Claude selecciona una herramienta
- Claude analiza la petición del usuario y la compara con todas las herramientas disponibles para seleccionar la más relevante.
- Utilizando el proceso de “pensamiento” del LLM, identifica las palabras clave necesarias para la herramienta correspondiente.
- Generación de respuesta (Respuesta API)
- Al finalizar el proceso, se genera como salida la petición de pensamiento, junto con la herramienta y los parámetros seleccionados.
Tras este proceso, ejecuta la función/herramienta seleccionada y utiliza su salida para generar otra respuesta si es necesario.
Esquema general de la herramienta

Este esquema sirve para comunicar al LLM los requisitos del proceso de llamada a la función. No llama directamente a ninguna función ni desencadena ninguna acción por sí mismo. Para garantizar una identificación precisa de las herramientas, debe facilitarse una descripción detallada de cada una de ellas. Properties del esquema se utilizan para identificar los parámetros que se pasarán posteriormente a la función.
Demostración
Vamos a construir herramientas para rastrear la web y encontrar el precio de cualquier acción.
Herramientas Esquema

En la herramienta scrape_website, se obtendrá la URL del sitio web desde la petición del usuario. En cuanto a la herramienta stock_price, identificará el nombre de la empresa a partir de la consulta del usuario y lo convertirá en un ticker yfinance.
Pregunta al usuario

Haciendo al bot dos consultas, una para cada herramienta, obtenemos los siguientes resultados:

El proceso de reflexión enumera todos los pasos que sigue el LLM para seleccionar con precisión la herramienta correcta para cada consulta y ejecutar las conversiones necesarias, tal como se describe en las descripciones de las herramientas.
Seleccionar la herramienta adecuada
Tendremos que escribir algún código adicional que active las funciones pertinentes en función de las condiciones.

Esta función sirve para activar el código apropiado basándose en el nombre de la herramienta recuperado en la respuesta LLM. En la primera condición, raspamos la URL del sitio web obtenida de la entrada Herramienta, mientras que en la segunda condición, obtenemos el ticker de la acción y lo pasamos a la biblioteca python yfinance.
Ejecutar las funciones
Pasaremos el ToolUseBlock completo en la función select_tool() para activar el código correspondiente.
Salidas
- Primera pregunta
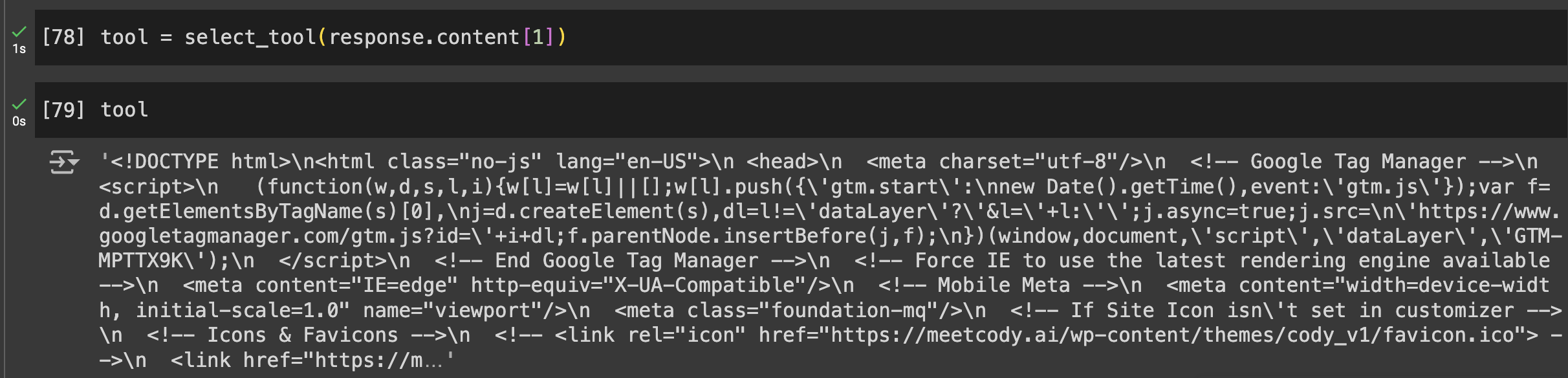
- Segunda pregunta
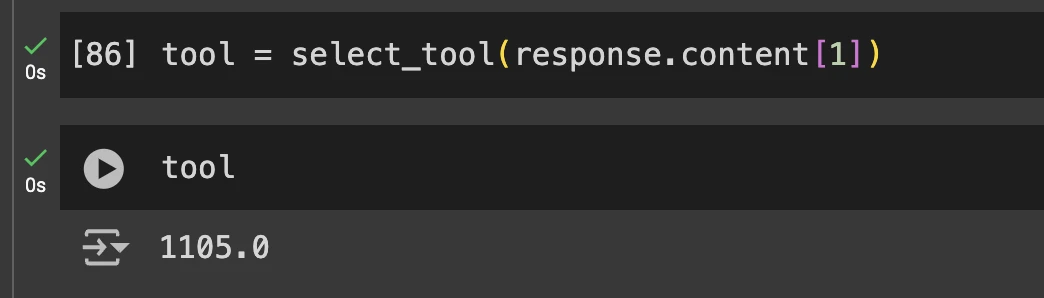

Si quieres ver el código fuente completo de esta demostración, puedes consultar este cuaderno.
Algunos casos prácticos
La función “uso de herramientas” para Claude eleva la versatilidad de la LLM a un nivel completamente nuevo. Aunque el ejemplo proporcionado es fundamental, sirve de base para ampliar la funcionalidad. He aquí una aplicación real de la misma:
¡Ayer @AnthropicAI lanzó una beta de uso de herramientas!
Aquí tienes un ejemplo de algo que construí con él: ¡un bot de atención al cliente que realmente puede resolver tu problema!
Estoy deseando ver qué más construye la gente! https://t.co/Xmi7pnwouS pic.twitter.com/T5bE4peexR
– Erik Schluntz (@ErikSchluntz) 5 de abril de 2024
Para encontrar más casos de uso, puedes visitar el repositorio oficial de Anthropic
aquí
.






















![Gemma] Construyendo un asistente de IA para la ciencia de datos 🤖](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEgg06dhS6iRpIv8hvyonlwncW-RC5n59E8vhaWRgIVqTP-Z1AbTBDtdJsX8ClDILimlGWlRAIORuZn8349TfUFmgqYyCRcoctTvNC_Kv70z41hCKd-0Fy4Ic4EgKyY0LxQ5rDt1eXi3jvEcTxgTC62glTl4e5Cffge50iiF0fxCBqmq9v-u7KTfIL4Lxb0/s1600/Gemma_social.png)