
كشفت شركة OpenAI النقاب عن أحدث ابتكاراتها في مجال الذكاء الاصطناعي، وهما نموذجا o1 و o1-Mini، مما يمثل قفزة كبيرة في تطور الذكاء الاصطناعي.
وتعطي هذه النماذج الأولوية لتعزيز قدرات التفكير وحل المشكلات، مما يضع معيارًا جديدًا في تكنولوجيا الذكاء الاصطناعي.
ويبرز هذا التقدم بشكل خاص لقدرته على التعامل مع المهام المعقدة بدقة وموثوقية محسّنة.
الأهمية والقدرات
يُظهِر نموذج OpenAI o1 المعروف بقدراته المنطقية القوية براعته في مجالات مثل البرمجة والرياضيات، متفوقاً على النماذج السابقة مثل GPT-4o.
وفي الوقت نفسه، يقدم نموذج o1-Mini حلاً فعالاً من حيث التكلفة لتطبيقات العلوم والتكنولوجيا والهندسة والرياضيات، ويتفوق في توليد الأكواد البرمجية ومهام الأمن السيبراني.
تم تصميم كلا النموذجين “للتفكير” قبل الاستجابة، باستخدام منهجية “سلسلة التفكير” الفريدة التي تحاكي التفكير البشري لحل المشكلات المعقدة بكفاءة. 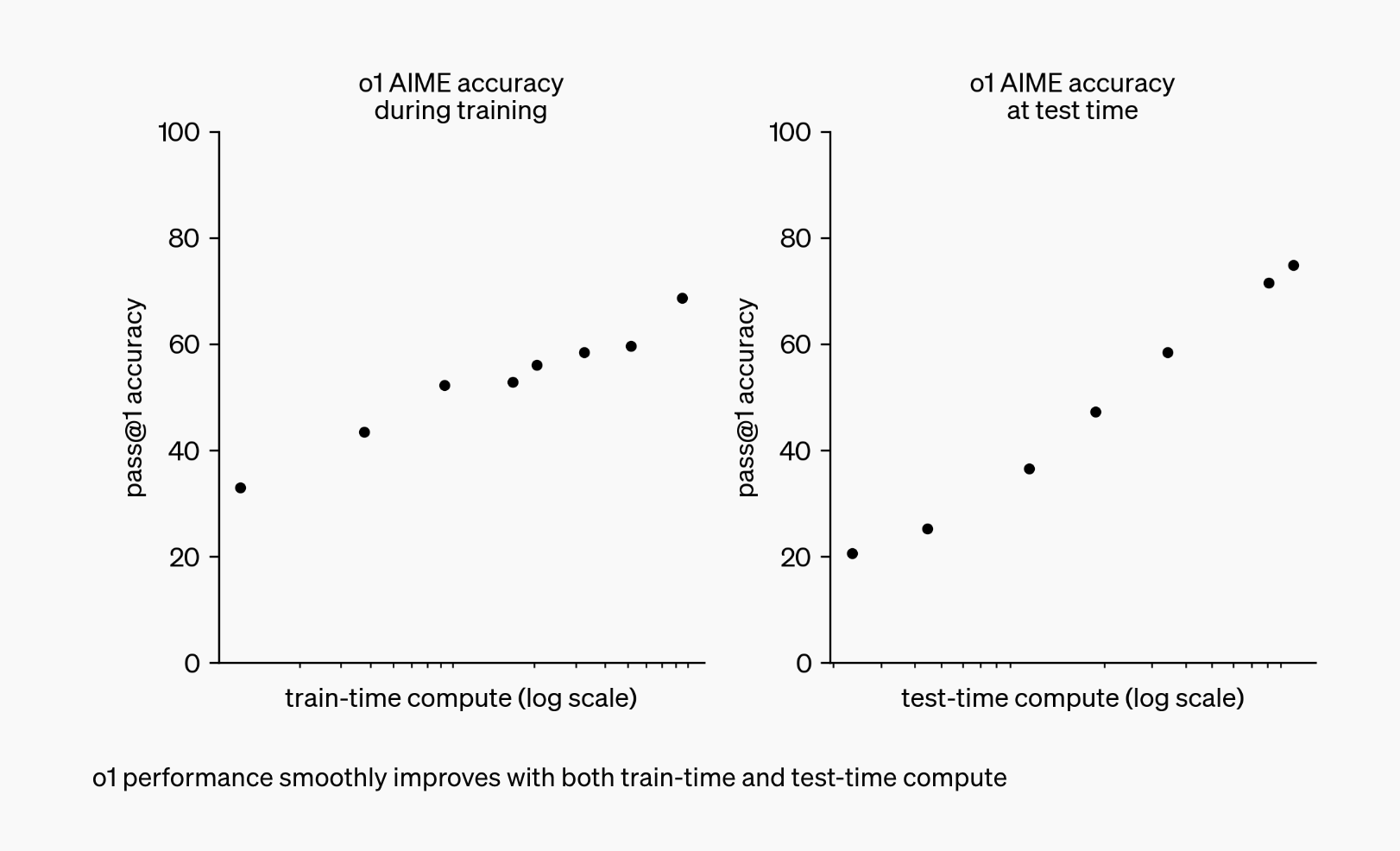
OpenAI o1: تطوير الاستدلال بالذكاء الاصطناعي
يُعدّ نموذج OpenAI o1 تطوراً رائداً في مجال الذكاء الاصطناعي، مع التركيز على قدرات التفكير المعززة.
يتميز هذا النموذج من خلال قدرته على معالجة المشاكل المعقدة بنهج مبتكر.
يوظف نموذج o1 تقنيات تدريب متقدمة مثل التعلم المعزز، الذي يسمح له بالتعلم من نجاحاته وأخطائه، ومنهجية “سلسلة التفكير” ، التي تقسم المسائل المعقدة إلى خطوات معقدة يمكن التحكم فيها على غرار العمليات المعرفية البشرية.
إن أداء o1 في مجالات مثل الرياضيات والبرمجة مثير للإعجاب بشكل خاص، حيث تفوق على سابقيه من خلال حل المشكلات المعقدة بدقة وسرعة أكبر.
وقد أظهر نتائج متفوقة في مسابقات البرمجة والرياضيات التنافسية، بما في ذلك أولمبياد الرياضيات الدولي، مما يدل على براعته في هذه المجالات.
يضع هذا النموذج معيارًا جديدًا لقدرات الذكاء الاصطناعي، مما يشير إلى خطوة كبيرة نحو تحقيق تفكير شبيه بالتفكير البشري في الذكاء الاصطناعي.
OpenAI o1-Mini: التميز في الذكاء الاصطناعي الفعال من حيث التكلفة
كبديل مناسب للميزانية، يقدم نموذج o1-Mini من OpenAI مزيجًا رائعًا من الكفاءة من حيث التكلفة وقدرات التفكير القوية.
صُمم o1-Mini خصيصًا لتطبيقات العلوم والتكنولوجيا والهندسة والرياضيات، ويتفوق في مجالات مثل الرياضيات والبرمجة والأمن السيبراني.
وقد حقق نتائج رائعة في معايير مثل Codeforces وCTFs للأمن السيبراني، مما يدل على كفاءته في المهام التقنية.
عند مقارنته بنظيره o1، فقد صُمم طراز o1-Mini ليكون أكثر فعالية من حيث التكلفة مع الحفاظ على مستويات أداء جديرة بالثناء.
على الرغم من أنه قد لا يضاهي القدرات الشاملة لـ o1 من حيث الاستدلال، إلا أنه يقدم حلاً عملياً للتطبيقات التي تتطلب حل المشكلات بسرعة وكفاءة بتكلفة أقل.
بالإضافة إلى ذلك، تُعد سرعة o1-Mini ميزة أخرى، مما يجعلها مناسبة للسيناريوهات التي تكون فيها الاستجابات السريعة ضرورية، وبالتالي توفر أداة متعددة الاستخدامات في مجال الذكاء الاصطناعي.
التسعير وإمكانية الوصول إلى OpenAI o1 و o1-Mini

يعكس تسعير OpenAI الاستراتيجي لنموذجي o1 و o1-Mini التزامها بجعل الذكاء الاصطناعي المتقدم متاحًا وفعالاً من حيث التكلفة.
صُممت استراتيجية تسعير OpenAI o1 لتلبية احتياجات القطاعات التي يكون فيها حل المشكلات المعقدة أمرًا بالغ الأهمية، مثل البحث العلمي ومهام البرمجة المتقدمة.
في المقابل، يوفر o1-Mini خيارًا أكثر توفيرًا وبأسعار معقولة، حيث يقدم أداءً ممتازًا في تطبيقات العلوم والتكنولوجيا والهندسة والرياضيات دون تكلفة أعلى.  مقارنةً بسابقيه، يُظهر كلا النموذجين فعالية محسّنة من حيث التكلفة.
مقارنةً بسابقيه، يُظهر كلا النموذجين فعالية محسّنة من حيث التكلفة.
على الرغم من أن o1 هو استثمار أكثر أهمية، إلا أن دقته وكفاءته في مهام التفكير المعقدة تبرر التكلفة.
وفي الوقت نفسه، فإن قدرة o1-Mini على تحمل التكاليف تجعله مناسبًا للتعليم والشركات الناشئة والشركات الصغيرة التي تتطلب حلول ذكاء اصطناعي موثوقة دون تكبد تكاليف باهظة.
تضمن استراتيجية التسعير التي تتبعها OpenAI إمكانية الوصول إلى هذه النماذج في مختلف القطاعات، مما يعزز من اعتمادها وابتكارها على نطاق أوسع.
الخاتمة: مستقبل الذكاء الاصطناعي مع الذكاء الاصطناعي المفتوح
يمثل تقديم نموذجي o1 و o1-Mini من OpenAI تقدماً كبيراً في تكنولوجيا الذكاء الاصطناعي، خاصةً في قدرات التفكير وحل المشكلات.
ومن المقرر أن تُحدث هذه النماذج ثورة في المجالات التي تتطلب مهام إدراكية معقدة، حيث توفر دقة وكفاءة غير مسبوقة.
ومع ريادة o1 في مجالات معقدة مثل البرمجة والرياضيات، وتوفير o1-Mini حلولاً فعالة من حيث التكلفة لتطبيقات العلوم والتكنولوجيا والهندسة والرياضيات، فإن OpenAI يمهد الطريق لمزيد من ابتكارات الذكاء الاصطناعي التي يمكن الوصول إليها.
وبالنظر إلى المستقبل، يشير تركيز OpenAI المستمر على تحسين قدرات هذه النماذج على التفكير المنطقي إلى مستقبل مشرق لدور الذكاء الاصطناعي في مختلف الصناعات.
ومع استمرار OpenAI في تحسين هذه النماذج، تزداد قدرتها على محاكاة التفكير الشبيه بقدرات البشر، مما يعد بتأثيرات تحويلية واعدة في البحث العلمي والتعليم وغيرهما.
في نهاية المطاف، يمثل نموذجا o1 و o1-Mini حقبة جديدة من تطوير الذكاء الاصطناعي، وهما على استعداد لإعادة تعريف كيفية مساعدة التكنولوجيا في حل تحديات العالم الحقيقي.






