
A OpenAI revelou suas mais recentes inovações em IA, os modelos o1 e o1-Mini, marcando um salto significativo na evolução da inteligência artificial.
Esses modelos priorizam recursos aprimorados de raciocínio e solução de problemas, estabelecendo um novo padrão na tecnologia de IA.
Esse avanço é particularmente notável por sua capacidade de lidar com tarefas complexas com maior precisão e confiabilidade.
Importância e recursos
O modelo OpenAI o1, conhecido por sua capacidade de raciocínio robusto, demonstra sua proeza em áreas como codificação e matemática, superando os modelos anteriores, como o GPT-4o.
Enquanto isso, o o1-Mini oferece uma solução econômica para aplicações STEM, destacando-se na geração de códigos e em tarefas de segurança cibernética.
Ambos os modelos foram projetados para “pensar” antes de responder, utilizando uma metodologia exclusiva de “cadeia de pensamento” que imita o raciocínio humano para resolver problemas complexos com eficiência. 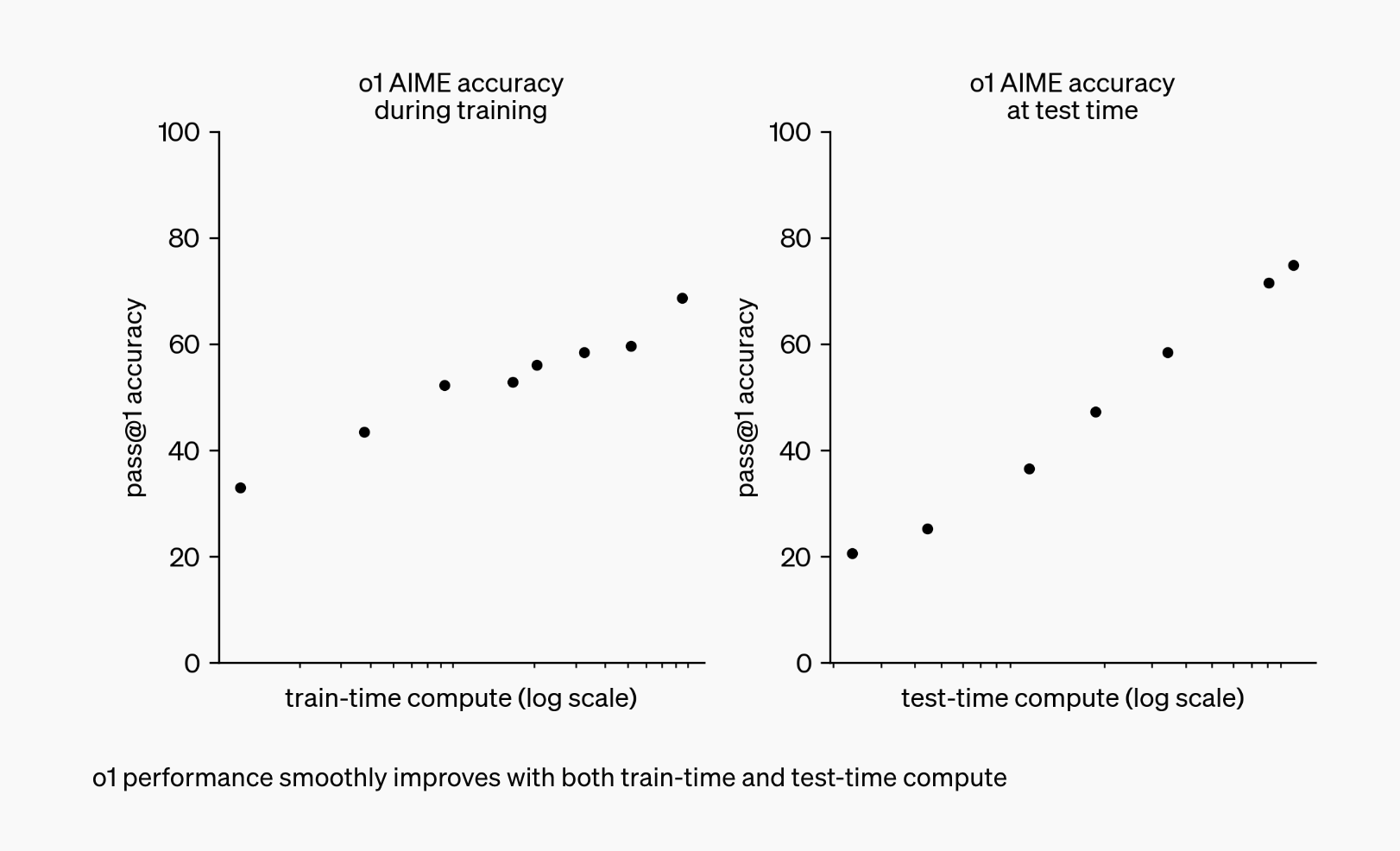
OpenAI o1: Avançando o raciocínio de IA
O modelo OpenAI o1 é um desenvolvimento inovador em IA, enfatizando recursos de raciocínio aprimorados.
Esse modelo se distingue por sua capacidade de lidar com problemas complexos com uma abordagem inovadora.
O modelo o1 emprega técnicas avançadas de treinamento, como o Reinforcement Learning (Aprendizado por reforço), que permite que ele aprenda com seus acertos e erros, e a metodologia “Chain of Thought” (Cadeia de pensamento), que divide questões complexas em etapas gerenciáveis, semelhantes aos processos cognitivos humanos.
O desempenho da o1 em domínios como matemática e codificação é particularmente impressionante, superando seus antecessores ao resolver problemas complexos com maior precisão e velocidade.
Ele demonstrou resultados superiores em competições de programação e matemática, incluindo a Olimpíada Internacional de Matemática, demonstrando sua proeza nesses campos.
Esse modelo estabelece um novo padrão de referência para os recursos de IA, indicando um avanço significativo em direção à obtenção de raciocínio semelhante ao humano na inteligência artificial.
OpenAI o1-Mini: Excelência em IA econômica
Como uma alternativa econômica, o modelo o1-Mini da OpenAI oferece uma combinação impressionante de economia e recursos de raciocínio robustos.
Adaptado especificamente para aplicações STEM, o o1-Mini se destaca em áreas como matemática, codificação e segurança cibernética.
Ele alcançou pontuações notáveis em benchmarks como Codeforces e CTFs de segurança cibernética, demonstrando sua proficiência em tarefas técnicas.
Quando comparado ao seu equivalente, o o1, o modelo o1-Mini foi projetado para ser mais econômico e, ao mesmo tempo, manter níveis de desempenho louváveis.
Embora possa não se equiparar aos recursos abrangentes do o1 em termos de raciocínio, ele oferece uma solução prática para aplicativos que exigem a resolução rápida e eficiente de problemas a um custo menor.
Além disso, a velocidade do o1-Mini é uma vantagem, o que o torna adequado para cenários em que respostas rápidas são essenciais, oferecendo assim uma ferramenta versátil no cenário da IA.
Preços e acessibilidade do OpenAI o1 e o1-Mini

O preço estratégico da OpenAI para os modelos o1 e o1-Mini reflete seu compromisso de tornar a IA avançada acessível e econômica.
A estratégia de preços do OpenAI o1 foi projetada para atender a setores em que a solução de problemas complexos é fundamental, como pesquisa científica e tarefas avançadas de codificação.
Em contrapartida, o o1-Mini oferece uma opção mais econômica, proporcionando excelente desempenho em aplicativos STEM sem o custo mais alto.  Em comparação com seus antecessores, ambos os modelos apresentam melhor custo-benefício.
Em comparação com seus antecessores, ambos os modelos apresentam melhor custo-benefício.
Embora o o1 seja um investimento mais significativo, sua precisão e eficiência em tarefas de raciocínio complexas justificam a despesa.
Enquanto isso, o preço acessível do o1-Mini o torna adequado para educação, startups e pequenas empresas que precisam de soluções confiáveis de IA sem incorrer em altos custos.
A estratégia de preços da OpenAI garante que esses modelos sejam acessíveis em vários setores, promovendo uma adoção e inovação mais amplas.
Conclusão: O futuro da IA com a OpenAI
A introdução dos modelos o1 e o1-Mini da OpenAI marca um avanço significativo na tecnologia de IA, especialmente nos recursos de raciocínio e solução de problemas.
Esses modelos estão prontos para revolucionar os campos que exigem tarefas cognitivas complexas, oferecendo precisão e eficiência sem precedentes.
Com o o1 liderando em áreas complexas, como codificação e matemática, e o o1-Mini fornecendo soluções econômicas para aplicações STEM, a OpenAI está abrindo caminho para inovações de IA mais acessíveis.
Olhando para o futuro, o foco contínuo da OpenAI em refinar as habilidades de raciocínio desses modelos sugere um futuro brilhante para o papel da IA em todos os setores.
À medida que a OpenAI aprimora ainda mais esses modelos, seu potencial para emular o raciocínio humano aumenta, prometendo impactos transformadores na pesquisa científica, na educação e em outros setores.
Em última análise, o o1 e o o1-Mini representam uma nova era de desenvolvimento de IA, pronta para redefinir a forma como a tecnologia auxilia na solução de desafios do mundo real.







