
OpenAI hat seine neuesten KI-Innovationen, die o1- und o1-Mini-Modelle, vorgestellt und damit einen bedeutenden Sprung in der Entwicklung der künstlichen Intelligenz gemacht.
Diese Modelle legen den Schwerpunkt auf verbesserte Denk- und Problemlösungsfähigkeiten und setzen damit einen neuen Standard in der KI-Technologie.
Dieser Fortschritt zeichnet sich insbesondere durch die Fähigkeit aus, komplexe Aufgaben mit verbesserter Genauigkeit und Zuverlässigkeit zu bewältigen.
Bedeutung und Fähigkeiten
Das Modell OpenAI o1, das für seine robusten Denkfähigkeiten bekannt ist, stellt seine Fähigkeiten in Bereichen wie Programmierung und Mathematik unter Beweis und übertrifft frühere Modelle wie GPT-4o.
Das Modell o1-Mini ist eine kostengünstige Lösung für MINT-Anwendungen und zeichnet sich durch Codegenerierung und Cybersicherheitsaufgaben aus.
Beide Modelle sind so konzipiert, dass sie “denken”, bevor sie reagieren. Sie verwenden eine einzigartige “Denkkette”, die das menschliche Denken nachahmt, um komplexe Probleme effizient zu lösen. 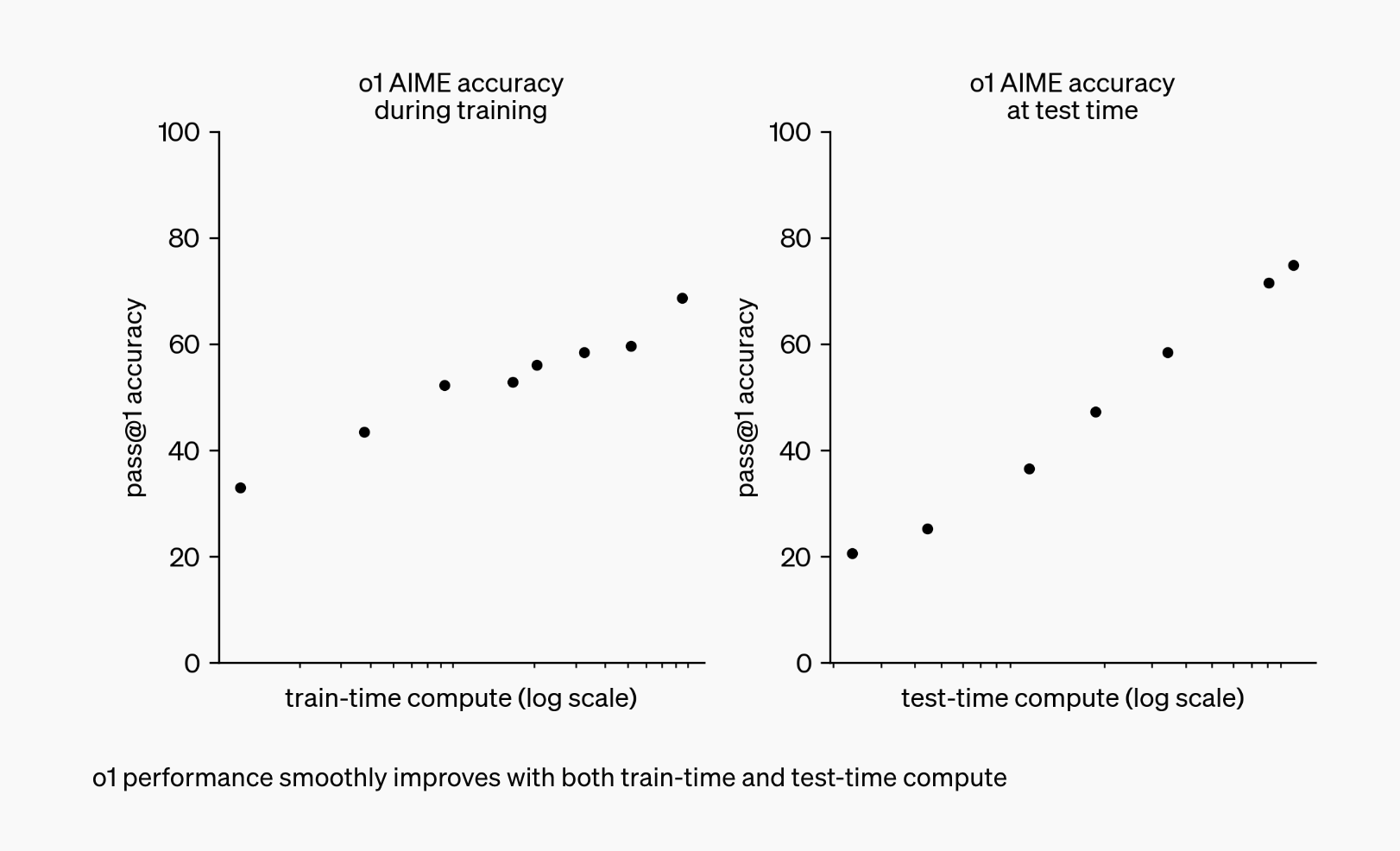
OpenAI o1: Fortschrittliches KI-Reasoning
Das OpenAI o1 Modell ist eine bahnbrechende Entwicklung in der KI, die den Schwerpunkt auf erweiterte Argumentationsfähigkeiten legt.
Dieses Modell zeichnet sich durch seine Fähigkeit aus, komplexe Probleme mit einem innovativen Ansatz anzugehen.
Das o1-Modell nutzt fortschrittliche Trainingstechniken wie das Reinforcement Learning, das es ihm ermöglicht, aus seinen Erfolgen und Fehlern zu lernen, und die “Chain of Thought” -Methode, die komplizierte Fragen in handhabbare Schritte zerlegt, ähnlich wie menschliche kognitive Prozesse.
Die Leistung von o1 in Bereichen wie Mathematik und Programmierung ist besonders beeindruckend. Es übertrifft seine Vorgänger, indem es komplexe Probleme mit größerer Genauigkeit und Geschwindigkeit löst.
Es hat bei Programmier- und Mathematikwettbewerben, einschließlich der Internationalen Mathematik-Olympiade, hervorragende Ergebnisse erzielt und damit sein Können in diesen Bereichen unter Beweis gestellt.
Dieses Modell setzt einen neuen Maßstab für KI-Fähigkeiten und ist ein bedeutender Schritt auf dem Weg zu einer menschenähnlichen Denkweise in der künstlichen Intelligenz.
OpenAI o1-Mini: Kosteneffiziente KI-Exzellenz
Als budgetfreundliche Alternative bietet das Modell o1-Mini von OpenAI eine beeindruckende Mischung aus Kosteneffizienz und robusten Argumentationsfähigkeiten.
Der o1-Mini wurde speziell für MINT-Anwendungen entwickelt und zeichnet sich in Bereichen wie Mathematik, Codierung und Cybersicherheit aus.
Er hat bei Benchmarks wie Codeforces und Cybersecurity CTFs bemerkenswerte Ergebnisse erzielt und damit seine Leistungsfähigkeit bei technischen Aufgaben unter Beweis gestellt.
Im Vergleich zu seinem Gegenstück, dem o1, ist das o1-Mini-Modell kostengünstiger und bietet dennoch eine lobenswerte Leistung.
Auch wenn es in Bezug auf die Argumentation nicht an die umfassenden Fähigkeiten von o1 heranreicht, bietet es eine praktische Lösung für Anwendungen, die eine schnelle und effiziente Problemlösung zu geringeren Kosten erfordern.
Darüber hinaus ist die Geschwindigkeit von o1-Mini ein Vorteil, der es für Szenarien geeignet macht, in denen schnelle Reaktionen erforderlich sind. Damit ist o1-Mini ein vielseitiges Werkzeug in der KI-Landschaft.
Preisgestaltung und Zugänglichkeit von OpenAI o1 und o1-Mini

Die strategische Preisgestaltung von OpenAI für die Modelle o1 und o1-Mini spiegelt das Engagement des Unternehmens wider, fortschrittliche KI zugänglich und kostengünstig zu machen.
Die Preisstrategie von OpenAI o1 ist auf Sektoren ausgerichtet, in denen komplexe Problemlösungen entscheidend sind, wie z.B. in der wissenschaftlichen Forschung und bei fortgeschrittenen Codierungsaufgaben.
Im Gegensatz dazu bietet o1-Mini eine erschwinglichere Option, die eine hervorragende Leistung in MINT-Anwendungen bietet, ohne dabei teurer zu sein.  Im Vergleich zu ihren Vorgängermodellen weisen beide Modelle eine verbesserte Kosteneffizienz auf.
Im Vergleich zu ihren Vorgängermodellen weisen beide Modelle eine verbesserte Kosteneffizienz auf.
Der o1 ist zwar eine größere Investition, aber seine Genauigkeit und Effizienz bei komplexen Denkaufgaben rechtfertigen die Kosten.
Der o1-Mini ist erschwinglich und eignet sich daher für Bildungseinrichtungen, Startups und kleine Unternehmen, die zuverlässige KI-Lösungen benötigen, ohne hohe Kosten zu verursachen.
Die Preisstrategie von OpenAI stellt sicher, dass diese Modelle für verschiedene Sektoren zugänglich sind, was eine breitere Akzeptanz und Innovation fördert.
Schlussfolgerung: Die Zukunft der KI mit OpenAI
Die Einführung der o1- und o1-Mini-Modelle von OpenAI stellt einen bedeutenden Fortschritt in der KI-Technologie dar, insbesondere in Bezug auf die Denk- und Problemlösungsfähigkeiten.
Diese Modelle werden die Bereiche, die komplexe kognitive Aufgaben erfordern, revolutionieren und eine noch nie dagewesene Genauigkeit und Effizienz bieten.
Mit o1, das in komplizierten Bereichen wie Programmierung und Mathematik führend ist, und o1-Mini, das kosteneffektive Lösungen für MINT-Anwendungen bietet, ebnet OpenAI den Weg für zugänglichere KI-Innovationen.
Mit Blick auf die Zukunft deutet der kontinuierliche Fokus von OpenAI auf die Verfeinerung der Denkfähigkeiten dieser Modelle auf eine glänzende Zukunft für die Rolle der KI in allen Branchen hin.
In dem Maße, in dem OpenAI diese Modelle weiter verbessert, steigt ihr Potenzial, menschenähnliches Denken zu emulieren, was transformative Auswirkungen auf die wissenschaftliche Forschung, die Bildung und darüber hinaus verspricht.
Letztendlich repräsentieren o1 und o1-Mini eine neue Ära der KI-Entwicklung, die die Art und Weise, wie Technologie bei der Lösung realer Herausforderungen hilft, neu definieren wird.






