
A capacidade de recuperar e processar dados de forma eficiente tornou-se um fator de mudança na atual era de tecnologia intensiva. Vamos explorar a forma como a API RAG redefine o processamento de dados. Esta abordagem inovadora combina as capacidades dos modelos de linguagem de grande dimensão (LLM) com técnicas baseadas na recuperação para revolucionar a recuperação de dados.
O que são Modelos de Linguagem de Grande Porte (LLMs)?
Os LLMs (Large Language Models) são sistemas avançados de inteligência artificial que servem como base para a RAG (Retrieval-Augmented Generation). Os LLM, como o GPT (Generative Pre-trained Transformer), são modelos de IA altamente sofisticados e orientados para a linguagem. Foram treinados em conjuntos de dados extensos e podem compreender e gerar texto semelhante ao humano, o que os torna indispensáveis para várias aplicações.
No contexto da API RAG, estes LLMs desempenham um papel central na melhoria da recuperação, processamento e geração de dados, tornando-a uma ferramenta versátil e poderosa para otimizar as interacções de dados.
Vamos simplificar o conceito de API RAG para si.
O que é RAG?
RAG, ou Retrieval-Augmented Generation, é um quadro concebido para otimizar a IA generativa. O seu principal objetivo é garantir que as respostas geradas pela IA não só estão actualizadas e são relevantes para o pedido de entrada, como também são exactas. Esta ênfase na exatidão é um aspeto fundamental da funcionalidade da API RAG. É uma forma inovadora de processar dados usando programas de computador super inteligentes chamados Modelos de Linguagem Grandes (LLMs), como o GPT.
Estes LLMs são como feiticeiros digitais que conseguem prever as palavras que vêm a seguir numa frase, compreendendo as palavras que as precedem. Aprenderam com toneladas de textos, por isso conseguem escrever de uma forma que soa muito humana. Com o RAG, pode utilizar estes assistentes digitais para o ajudar a encontrar e trabalhar com dados de forma personalizada. É como ter um amigo muito inteligente que sabe tudo sobre dados a ajudá-lo!
Essencialmente, o RAG injeta dados recuperados por meio de pesquisa semântica na consulta feita ao LLM para referência. Vamos nos aprofundar nessas terminologias mais adiante neste artigo.
Para saber mais sobre o RAG em detalhes, confira este artigo abrangente da Cohere
RAG vs. ajuste fino: Qual é a diferença?
| Aspeto | API RAG | Afinação |
|---|---|---|
| Abordagem | Aumenta os LLMs existentes com o contexto da sua base de dados | Especializa o LLM para tarefas específicas |
| Recursos informáticos | Requer menos recursos computacionais | Exige recursos computacionais substanciais |
| Requisitos de dados | Adequado para conjuntos de dados mais pequenos | Requer grandes quantidades de dados |
| Especificidade do modelo | Agnóstico em relação ao modelo; pode mudar de modelo conforme necessário | Específico do modelo; normalmente é bastante entediante mudar de LLM |
| Adaptabilidade do domínio | Independente do domínio, versátil em várias aplicações | Pode ser necessário adaptá-lo a diferentes domínios |
| Redução das alucinações | Reduz eficazmente as alucinações | Pode ter mais alucinações se não for cuidadosamente afinada |
| Casos de utilização comuns | Ideal para sistemas de perguntas e respostas (QA), várias aplicações | Tarefas especializadas, como a análise de documentos médicos, etc. |
O papel da base de dados vetorial
A base de dados vetorial é fundamental na geração aumentada de recuperação (RAG) e nos modelos de língua de grande dimensão (LLM). Servem de base para melhorar a recuperação de dados, o aumento do contexto e o desempenho geral destes sistemas. Aqui está uma exploração do papel fundamental das bases de dados vectoriais:
Ultrapassar as limitações das bases de dados estruturadas
As bases de dados estruturadas tradicionais são frequentemente insuficientes quando utilizadas na API RAG devido à sua natureza rígida e predefinida. Têm dificuldade em lidar com os requisitos flexíveis e dinâmicos da alimentação de informações contextuais aos LLM. As bases de dados vectoriais vêm colmatar esta limitação.
Armazenamento eficiente de dados em forma de vetor
As bases de dados vectoriais são excelentes para armazenar e gerir dados utilizando vectores numéricos. Este formato permite uma representação versátil e multidimensional dos dados. Estes vectores podem ser processados de forma eficiente, facilitando a recuperação avançada de dados.
Relevância e desempenho dos dados
Os sistemas RAG podem aceder e recuperar rapidamente informações contextuais relevantes, tirando partido das bases de dados vectoriais. Esta recuperação eficiente é crucial para aumentar a velocidade e a precisão das respostas geradas pelos LLMs.
Agrupamento e análise multidimensional
Os vectores podem agrupar e analisar pontos de dados num espaço multidimensional. Esta caraterística é inestimável para o RAG, permitindo que os dados contextuais sejam agrupados, relacionados e apresentados de forma coerente aos LLM. Isto conduz a uma melhor compreensão e à geração de respostas contextualizadas.
O que é a pesquisa semântica?
A pesquisa semântica é uma pedra angular da API Retrieval-Augmented Generation (RAG) e dos modelos de linguagem de grande dimensão (LLM). A sua importância não pode ser subestimada, revolucionando a forma como a informação é acedida e compreendida.
Para além da base de dados tradicional
A pesquisa semântica ultrapassa as limitações das bases de dados estruturadas, que muitas vezes têm dificuldade em lidar com requisitos de dados dinâmicos e flexíveis. Em vez disso, recorre a bases de dados de vectores, permitindo uma gestão de dados mais versátil e adaptável, crucial para o sucesso dos GCR e dos LLM.
Análise Multidimensional
Um dos principais pontos fortes da pesquisa semântica é a sua capacidade de compreender os dados sob a forma de vectores numéricos. Esta análise multidimensional melhora a compreensão das relações entre os dados com base no contexto, permitindo a criação de conteúdos mais coerentes e conscientes do contexto.
Recuperação eficiente de dados
A eficiência é vital na recuperação de dados, especialmente para a geração de respostas em tempo real em sistemas API RAG. A pesquisa semântica optimiza o acesso aos dados, melhorando significativamente a velocidade e a precisão da geração de respostas utilizando LLMs. Trata-se de uma solução versátil que pode ser adaptada a várias aplicações, desde análises médicas a consultas complexas, reduzindo simultaneamente as imprecisões nos conteúdos gerados por IA.
O que é a API RAG?
Pense na API do RAG como o RAG como um serviço. Ele reúne todos os fundamentos de um sistema RAG em um único pacote, o que torna conveniente empregar um sistema RAG em sua organização. A API do RAG permite que você se concentre nos principais elementos de um sistema RAG e deixe a API cuidar do resto.
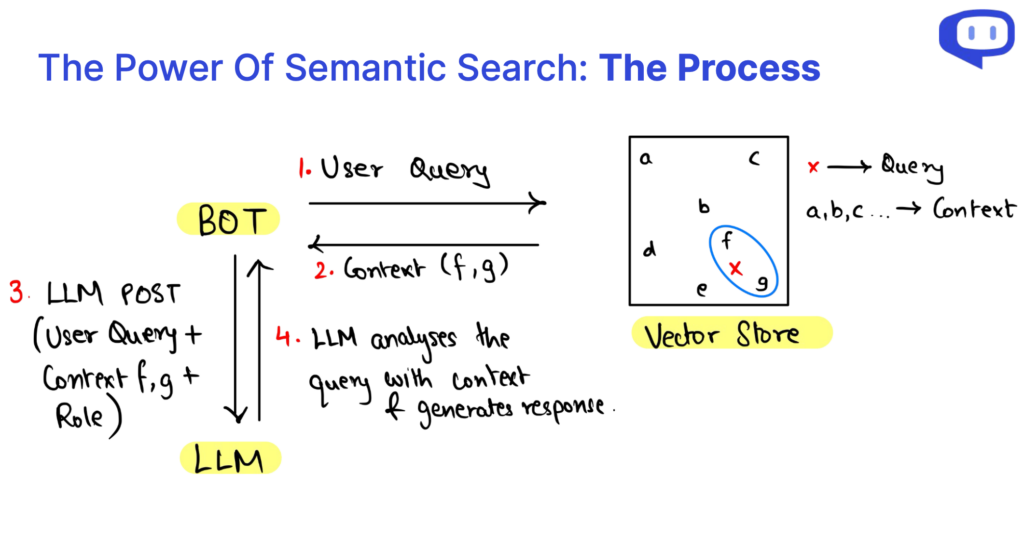
Quais são os 3 elementos das consultas da API RAG?

Quando mergulhamos nos meandros da Geração Aumentada por Recuperação (RAG), descobrimos que uma consulta RAG pode ser dissecada em três elementos cruciais: O contexto, a função e a consulta do utilizador. Estes componentes são os blocos de construção que alimentam o sistema RAG, desempenhando cada um deles um papel vital no processo de geração de conteúdos.
Os O contexto constitui a base de uma consulta da API RAG, servindo como repositório de conhecimentos onde residem as informações essenciais. O aproveitamento da pesquisa semântica nos dados da base de conhecimentos existente permite um contexto dinâmico relevante para a consulta do utilizador.
O papel Papel define o objetivo do sistema RAG, orientando-o para a realização de tarefas específicas. Orienta o modelo na geração de conteúdos adaptados aos requisitos, oferecendo explicações, respondendo a perguntas ou resumindo informações.
A Consulta do utilizador é a entrada do utilizador, assinalando o início do processo RAG. Representa a interação do utilizador com o sistema e comunica as suas necessidades de informação.
O processo de recuperação de dados no âmbito da API RAG é tornado eficiente pela pesquisa semântica. Esta abordagem permite a análise de dados multidimensionais, melhorando a nossa compreensão das relações entre os dados com base no contexto. Em suma, a compreensão da anatomia das consultas RAG e da recuperação de dados através da pesquisa semântica permite-nos desbloquear o potencial desta tecnologia, facilitando o acesso eficiente ao conhecimento e a geração de conteúdos sensíveis ao contexto.
Como melhorar a relevância com prompts?
A engenharia de prompts é fundamental para orientar os grandes modelos linguísticos (LLM) do RAG para gerar respostas contextualmente relevantes para um domínio específico.
Embora a capacidade da Geração Aumentada por Recuperação (RAG) para tirar partido do contexto seja uma capacidade formidável, fornecer apenas o contexto nem sempre é suficiente para garantir respostas de alta qualidade. É aqui que entra o conceito de prompts.
Um prompt bem elaborado serve como um roteiro para o LLM, orientando-o para a resposta desejada. Normalmente, inclui os seguintes elementos:
Desbloquear a relevância contextual
A geração aumentada por recuperação (RAG) é uma ferramenta poderosa para tirar partido do contexto. No entanto, o mero contexto pode não ser suficiente para garantir respostas de elevada qualidade. É aqui que os prompts são cruciais para orientar os grandes modelos linguísticos (LLMs) no RAG para gerar respostas que se alinham com domínios específicos.
Roteiro para criar uma função de bot para seu caso de uso
Um prompt bem estruturado funciona como um roteiro, orientando os LLMs para as respostas desejadas. Normalmente, é composto por vários elementos:
Identidade do Bot
Ao mencionar o nome do bot, estabelece a sua identidade na interação, tornando a conversa mais pessoal.
Definição da tarefa
A definição clara da tarefa ou função que o LLM deve desempenhar garante que ele satisfaça as necessidades do utilizador, seja fornecendo informações, respondendo a perguntas ou qualquer outra tarefa específica.
Especificação do tom
A especificação do tom ou estilo de resposta pretendido define o ambiente adequado para a interação, seja ela formal, amigável ou informativa.
Instruções diversas
Esta categoria pode abranger uma série de directivas, incluindo a adição de ligações e imagens, a apresentação de saudações ou a recolha de dados específicos.
Criação de relevância contextual
A elaboração cuidadosa dos prompts é uma abordagem estratégica para garantir que a sinergia entre o RAG e os LLM resulta em respostas contextualmente conscientes e altamente pertinentes para as necessidades do utilizador, melhorando a experiência geral do utilizador.
Porquê escolher a API RAG da Cody?
Agora que já desvendámos o significado do RAG e dos seus componentes principais, vamos apresentar a Cody como o parceiro ideal para tornar o RAG uma realidade. A Cody oferece uma API RAG abrangente que combina todos os elementos essenciais necessários para uma recuperação e processamento de dados eficientes, tornando-a a melhor escolha para o seu percurso RAG.
Modelo Agnóstico
Você não precisa se preocupar em trocar de modelo para se manter atualizado com as últimas tendências de IA. Com a API RAG da Cody, você pode alternar facilmente entre modelos de idiomas grandes em tempo real, sem custo adicional.
Versatilidade inigualável
A API RAG da Cody apresenta uma versatilidade notável, lidando eficazmente com vários formatos de ficheiros e reconhecendo hierarquias textuais para uma organização óptima dos dados.
Algoritmo de fragmentação personalizado
A sua caraterística de destaque reside nos seus algoritmos de fragmentação avançados, que permitem uma segmentação abrangente dos dados, incluindo metadados, garantindo uma gestão de dados superior.
Velocidade superior à concorrência
Garante uma recuperação de dados extremamente rápida em escala com um tempo de consulta linear, independentemente do número de índices. Garante resultados rápidos para as suas necessidades de dados.
Integração e suporte contínuos
A Cody oferece uma integração perfeita com plataformas populares e um suporte abrangente, melhorando a sua experiência RAG e solidificando a sua posição como a melhor escolha para a recuperação e processamento eficientes de dados. Assegura uma interface de utilizador intuitiva que não requer conhecimentos técnicos, tornando-a acessível e fácil de utilizar por indivíduos de todos os níveis de competências, simplificando ainda mais a experiência de recuperação e processamento de dados.
Funcionalidades da API RAG que melhoram as interacções de dados
Na nossa exploração da Geração Aumentada por Recuperação (RAG), descobrimos uma solução versátil que integra Modelos de Linguagem de Grande Dimensão (LLM) com pesquisa semântica, bases de dados vectoriais e avisos para melhorar a recuperação e o processamento de dados.
O RAG, sendo agnóstico em relação ao modelo e ao domínio, é muito promissor em diversas aplicações. A API RAG da Cody eleva esta promessa ao oferecer funcionalidades como o tratamento flexível de ficheiros, a fragmentação avançada, a recuperação rápida de dados e as integrações perfeitas. Esta combinação está preparada para revolucionar o envolvimento dos dados.
Está preparado para abraçar esta transformação de dados? Redefina as suas interacções de dados e explore uma nova era no processamento de dados com a IA da Cody.
Perguntas frequentes
1. Qual é a diferença entre RAG e modelos de língua de grande porte (LLMs)?
A API RAG (Retrieval-Augmented Generation API) e os LLMs (Large Language Models) funcionam em conjunto.
A API RAG é uma interface de programação de aplicativos que combina dois elementos essenciais: um mecanismo de recuperação e um modelo de linguagem generativo (LLM). O seu principal objetivo é melhorar a recuperação de dados e a geração de conteúdos, centrando-se fortemente nas respostas sensíveis ao contexto. A API RAG é frequentemente aplicada a tarefas específicas, como a resposta a perguntas, a geração de conteúdos e a sumarização de textos. Foi concebido para dar respostas contextualmente relevantes às consultas dos utilizadores.
Os LLM (Large Language Models), por outro lado, constituem uma categoria mais vasta de modelos linguísticos como o GPT (Generative Pre-trained Transformer). Estes modelos são pré-treinados em conjuntos de dados extensos, permitindo-lhes gerar texto semelhante ao humano para várias tarefas de processamento de linguagem natural. Embora possam lidar com a recuperação e a geração, a sua versatilidade estende-se a várias aplicações, incluindo tradução, análise de sentimentos, classificação de textos e muito mais.
Na sua essência, a API RAG é uma ferramenta especializada que combina a recuperação e a geração de respostas sensíveis ao contexto em aplicações específicas. Os LLM, em contrapartida, são modelos linguísticos fundamentais que servem de base a várias tarefas de processamento da linguagem natural, oferecendo uma gama mais alargada de potenciais aplicações para além da simples recuperação e geração.
2. RAG e LLM – O que é melhor e porquê?
A escolha entre API RAG e LLMs depende das suas necessidades específicas e da natureza da tarefa que pretende realizar. Segue-se uma análise das considerações para o ajudar a determinar qual é a melhor opção para a sua situação:
Selecionar API RAG Se:
Necessita de respostas sensíveis ao contexto
A API RAG destaca-se por fornecer respostas contextualmente relevantes. Se a sua tarefa envolve responder a perguntas, resumir conteúdos ou gerar respostas específicas do contexto, a API RAG é uma escolha adequada.
Tem casos de utilização específicos
Se a sua aplicação ou serviço tiver casos de utilização bem definidos que exijam conteúdos sensíveis ao contexto, a API RAG pode ser mais adequada. Foi concebido especificamente para aplicações em que o contexto desempenha um papel crucial.
Necessita de um controlo preciso
A API RAG permite o ajuste fino e a personalização, o que pode ser vantajoso se tiver requisitos ou restrições específicos para o seu projeto.
Escolha LLMs se:
Necessita de versatilidade
Os LLM, tal como os modelos GPT, são altamente versáteis e podem lidar com uma vasta gama de tarefas de processamento de linguagem natural. Se as suas necessidades abrangem várias aplicações, os LLM oferecem flexibilidade.
Pretende criar soluções personalizadas
Pode criar soluções personalizadas de processamento de linguagem natural e ajustá-las ao seu caso de utilização específico ou integrá-las nos seus fluxos de trabalho existentes.
Necessita de uma compreensão linguística previamente treinada
Os LLMs são pré-treinados em vastos conjuntos de dados, o que significa que têm uma forte compreensão linguística imediata. Se precisar de trabalhar com grandes volumes de dados de texto não estruturados, os LLM podem ser uma mais-valia.
3. Porque é que os LLM, tal como os modelos GPT, são tão populares no processamento de linguagem natural?
Os LLM têm merecido uma atenção generalizada devido ao seu desempenho excecional em várias tarefas linguísticas. Os LLMs são treinados em grandes conjuntos de dados. Como resultado, eles podem compreender e produzir textos coerentes, contextualmente relevantes e gramaticalmente corretos, entendendo as nuances de qualquer idioma. Além disso, a acessibilidade de LLMs pré-treinados tornou a compreensão e a geração de linguagem natural com base em IA acessíveis a um público mais vasto.
4. Quais são algumas aplicações típicas dos LLMs?
Os LLMs encontram aplicações num vasto espetro de tarefas linguísticas, incluindo:
Compreensão de linguagem natural
Os LLMs destacam-se em tarefas como a análise de sentimentos, o reconhecimento de entidades nomeadas e a resposta a perguntas. As suas robustas capacidades de compreensão linguística tornam-nos valiosos para extrair informações de dados de texto.
Geração de texto
Podem gerar texto semelhante ao humano para aplicações como chatbots e geração de conteúdos, fornecendo respostas coerentes e contextualmente relevantes.
Tradução automática
Melhoraram significativamente a qualidade da tradução automática. Podem traduzir textos entre línguas com um nível notável de exatidão e fluência.
Sumarização de conteúdo
São competentes na criação de resumos concisos de documentos extensos ou transcrições, proporcionando uma forma eficiente de destilar informações essenciais de conteúdos extensos.
5. Como podem os LLMs manter-se actualizados com dados recentes e tarefas em evolução?
É fundamental garantir que os programas de formação de LLM se mantenham actuais e eficazes. São utilizadas várias estratégias para as manter actualizadas com novos dados e tarefas em evolução:
Aumento de dados
O aumento contínuo dos dados é essencial para evitar a degradação do desempenho resultante de informações desactualizadas. Aumentar o armazenamento de dados com informações novas e relevantes ajuda o modelo a manter a sua exatidão e relevância.
Reciclagem
A reciclagem periódica dos LLMs com novos dados é uma prática comum. O aperfeiçoamento do modelo com base em dados recentes garante a sua adaptação à evolução das tendências e mantém-se atualizado.
Aprendizagem ativa
A aplicação de técnicas de aprendizagem ativa é outra abordagem. Isto implica a identificação de instâncias em que o modelo é incerto ou suscetível de cometer erros e a recolha de anotações para essas instâncias. Estas anotações ajudam a aperfeiçoar o desempenho do modelo e a manter a sua precisão.