
Co to jest RAG API i jak działa?
Zdolność do wydajnego pobierania i przetwarzania danych stała się przełomem w dzisiejszej erze technologii. Przyjrzyjmy się, jak RAG API na nowo definiuje przetwarzanie danych. To innowacyjne podejście łączy w sobie sprawność dużych modeli językowych (LLM) z technikami opartymi na wyszukiwaniu, aby zrewolucjonizować wyszukiwanie danych.
Czym są duże modele językowe (LLM)?
Duże modele językowe (LLM) są zaawansowanymi systemami sztucznej inteligencji, które służą jako podstawa dla Retrieval-Augmented Generation (RAG). Modele LLM, takie jak GPT (Generative Pre-trained Transformer), są wysoce zaawansowanymi modelami sztucznej inteligencji opartymi na języku. Zostały one przeszkolone na obszernych zbiorach danych i mogą rozumieć i generować tekst podobny do ludzkiego, co czyni je niezbędnymi w różnych zastosowaniach.
W kontekście API RAG, te LLM odgrywają kluczową rolę w usprawnianiu wyszukiwania, przetwarzania i generowania danych, czyniąc z niego wszechstronne i potężne narzędzie do optymalizacji interakcji z danymi.
Uprośćmy koncepcję interfejsu API RAG.
Co to jest RAG?
RAG, czyli Retrieval-Augmented Generation, to framework zaprojektowany w celu optymalizacji generatywnej sztucznej inteligencji. Jego głównym celem jest zapewnienie, że odpowiedzi generowane przez sztuczną inteligencję są nie tylko aktualne i adekwatne do zapytania wejściowego, ale także dokładne. Skupienie się na dokładności jest kluczowym aspektem funkcjonalności RAG API. Jest to przełomowy sposób przetwarzania danych przy użyciu super-inteligentnych programów komputerowych zwanych dużymi modelami językowymi (LLM), takich jak GPT.
Te LLM są jak cyfrowi czarodzieje, którzy potrafią przewidzieć, jakie słowa będą następne w zdaniu, rozumiejąc słowa przed nimi. Nauczyli się z ton tekstu, więc mogą pisać w sposób, który brzmi bardzo ludzko. Dzięki RAG możesz korzystać z tych cyfrowych kreatorów, które pomogą Ci znaleźć dane i pracować z nimi w niestandardowy sposób. To jak mieć naprawdę mądrego przyjaciela, który wie wszystko o danych, pomagając ci!
Zasadniczo RAG wprowadza dane pobrane za pomocą wyszukiwania semantycznego do zapytania skierowanego do LLM w celu odniesienia. Zagłębimy się w te terminologie w dalszej części artykułu.
Aby dowiedzieć się więcej o RAG, zapoznaj się z tym obszernym artykułem autorstwa Cohere
RAG vs. Fine-Tuning: Jaka jest różnica?
| Aspekt | RAG API | Dostrajanie |
|---|---|---|
| Podejście | Uzupełnia istniejące LLM o kontekst z bazy danych użytkownika | Specjalizuje LLM do określonych zadań |
| Zasoby obliczeniowe | Wymaga mniejszej ilości zasobów obliczeniowych | Wymaga znacznych zasobów obliczeniowych |
| Wymagania dotyczące danych | Odpowiedni dla mniejszych zbiorów danych | Wymaga ogromnych ilości danych |
| Specyfika modelu | Niezależność od modelu; możliwość przełączania modeli w razie potrzeby | Specyficzne dla modelu; zazwyczaj dość żmudne przełączanie LLM |
| Zdolność adaptacji domeny | Niezależny od domeny, wszechstronny w różnych zastosowaniach | Może wymagać dostosowania do różnych domen |
| Redukcja halucynacji | Skutecznie zmniejsza halucynacje | Może doświadczać więcej halucynacji bez dokładnego dostrojenia. |
| Typowe przypadki użycia | Idealny do systemów pytań i odpowiedzi (QA), różnych aplikacji | Specjalistyczne zadania, takie jak analiza dokumentów medycznych itp. |
Rola wektorowej bazy danych
Wektorowa baza danych ma kluczowe znaczenie w generowaniu rozszerzonym o wyszukiwanie (RAG) i dużych modelach językowych (LLM). Służą one jako podstawa do ulepszania wyszukiwania danych, rozszerzania kontekstu i ogólnej wydajności tych systemów. Oto analiza kluczowej roli wektorowych baz danych:
Pokonywanie ograniczeń strukturalnej bazy danych
Tradycyjne strukturalne bazy danych często nie sprawdzają się, gdy są używane w RAG API ze względu na ich sztywny i predefiniowany charakter. Z trudem radzą sobie z elastycznymi i dynamicznymi wymaganiami dotyczącymi dostarczania informacji kontekstowych do LLM. Wektorowe bazy danych stanowią odpowiedź na to ograniczenie.
Wydajne przechowywanie danych w postaci wektorowej
Wektorowe bazy danych doskonale sprawdzają się w przechowywaniu i zarządzaniu danymi przy użyciu wektorów numerycznych. Format ten pozwala na wszechstronną i wielowymiarową reprezentację danych. Wektory te mogą być efektywnie przetwarzane, ułatwiając zaawansowane wyszukiwanie danych.
Adekwatność i wydajność danych
Systemy RAG mogą szybko uzyskiwać dostęp i pobierać odpowiednie informacje kontekstowe, wykorzystując wektorowe bazy danych. To skuteczne wyszukiwanie jest kluczowe dla zwiększenia szybkości i dokładności generowania odpowiedzi przez LLM.
Klastrowanie i analiza wielowymiarowa
Wektory mogą grupować i analizować punkty danych w wielowymiarowej przestrzeni. Funkcja ta jest nieoceniona dla RAG, umożliwiając grupowanie, powiązanie i spójną prezentację danych kontekstowych dla LLM. Prowadzi to do lepszego zrozumienia i generowania odpowiedzi uwzględniających kontekst.
Czym jest wyszukiwanie semantyczne?
Wyszukiwanie semantyczne jest kamieniem węgielnym w API Retrieval-Augmented Generation (RAG) i dużych modelach językowych (LLM). Jego znaczenie jest nie do przecenienia, rewolucjonizując sposób, w jaki informacje są dostępne i rozumiane.
Więcej niż tradycyjna baza danych
Wyszukiwanie semantyczne wykracza poza ograniczenia strukturalnych baz danych, które często mają trudności z obsługą dynamicznych i elastycznych wymagań dotyczących danych. Zamiast tego wykorzystuje wektorowe bazy danych, umożliwiając bardziej wszechstronne i elastyczne zarządzanie danymi, co ma kluczowe znaczenie dla sukcesu RAG i LLM.
Analiza wielowymiarowa
Jedną z kluczowych zalet wyszukiwania semantycznego jest jego zdolność do rozumienia danych w postaci wektorów liczbowych. Ta wielowymiarowa analiza poprawia zrozumienie relacji danych w oparciu o kontekst, umożliwiając bardziej spójne i kontekstowe generowanie treści.
Wydajne pobieranie danych
Wydajność ma kluczowe znaczenie w wyszukiwaniu danych, zwłaszcza w przypadku generowania odpowiedzi w czasie rzeczywistym w systemach RAG API. Wyszukiwanie semantyczne optymalizuje dostęp do danych, znacznie poprawiając szybkość i dokładność generowania odpowiedzi przy użyciu LLM. Jest to wszechstronne rozwiązanie, które można dostosować do różnych zastosowań, od analizy medycznej po złożone zapytania, jednocześnie zmniejszając niedokładności w treściach generowanych przez sztuczną inteligencję.
Co to jest RAG API?
Potraktuj RAG API jako usługę RAG-as-a-Service. Zestawia wszystkie podstawy systemu RAG w jednym pakiecie, dzięki czemu wygodnie jest zastosować system RAG w swojej organizacji. RAG API pozwala skupić się na głównych elementach systemu RAG i pozwolić API zająć się resztą.
Jakie są 3 elementy zapytań API RAG?

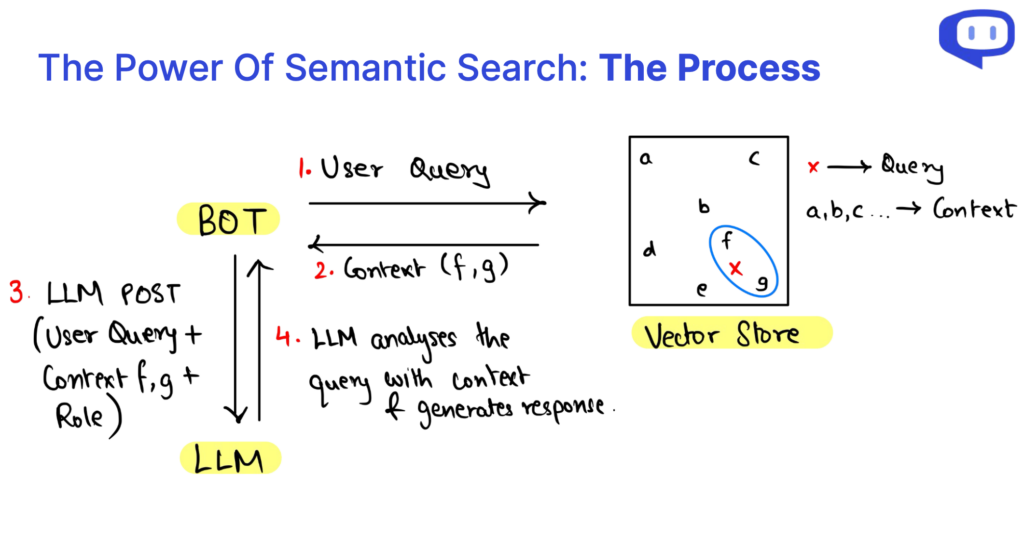
Kiedy zagłębimy się w zawiłości Retrieval-Augmented Generation (RAG), odkryjemy, że zapytanie RAG można podzielić na trzy kluczowe elementy: Kontekst, Rola i Zapytanie użytkownika. Komponenty te są elementami składowymi, które zasilają system RAG, a każdy z nich odgrywa istotną rolę w procesie generowania treści.
The Kontekst stanowi podstawę zapytania API RAG, służąc jako repozytorium wiedzy, w którym znajdują się istotne informacje. Wykorzystanie wyszukiwania semantycznego na istniejących danych bazy wiedzy pozwala na dynamiczny kontekst odpowiedni do zapytania użytkownika.
The Rola definiuje cel systemu RAG, kierując go do wykonywania określonych zadań. Prowadzi model w generowaniu treści dostosowanych do wymagań, oferując wyjaśnienia, odpowiadając na zapytania lub podsumowując informacje.
The Zapytanie użytkownika to dane wejściowe użytkownika, sygnalizujące rozpoczęcie procesu RAG. Reprezentuje interakcję użytkownika z systemem i komunikuje jego potrzeby informacyjne.
Proces wyszukiwania danych w RAG API jest wydajny dzięki wyszukiwaniu semantycznemu. Podejście to umożliwia wielowymiarową analizę danych, poprawiając nasze zrozumienie relacji danych w oparciu o kontekst. Krótko mówiąc, zrozumienie anatomii zapytań RAG i pobierania danych za pomocą wyszukiwania semantycznego pozwala nam uwolnić potencjał tej technologii, ułatwiając efektywny dostęp do wiedzy i generowanie treści z uwzględnieniem kontekstu.
Jak poprawić trafność za pomocą podpowiedzi?
Inżynieria podpowiedzi ma kluczowe znaczenie w sterowaniu dużymi modelami językowymi (LLM) w ramach RAG w celu generowania kontekstowo istotnych odpowiedzi dla określonej domeny.
Podczas gdy zdolność Retrieval-Augmented Generation (RAG) do wykorzystania kontekstu jest ogromną zdolnością, samo zapewnienie kontekstu nie zawsze jest wystarczające do zapewnienia wysokiej jakości odpowiedzi. W tym miejscu pojawia się koncepcja podpowiedzi.
Dobrze przygotowana podpowiedź służy jako mapa drogowa dla LLM, kierując go w stronę pożądanej odpowiedzi. Zazwyczaj zawiera ona następujące elementy:
Odblokowywanie trafności kontekstowej
Retrieval-augmented generation (RAG) to potężne narzędzie do wykorzystywania kontekstu. Jednak sam kontekst może nie wystarczyć do zapewnienia wysokiej jakości odpowiedzi. W tym miejscu podpowiedzi mają kluczowe znaczenie w sterowaniu dużymi modelami językowymi (LLM) w ramach RAG w celu generowania odpowiedzi zgodnych z określonymi domenami.
Mapa drogowa tworzenia roli bota dla danego przypadku użycia
Dobrze skonstruowany monit działa jak mapa drogowa, kierując LLM w stronę pożądanych odpowiedzi. Zazwyczaj składa się z różnych elementów:
Tożsamość bota
Wymieniając nazwę bota, ustalasz jego tożsamość w interakcji, dzięki czemu rozmowa staje się bardziej osobista.
Definicja zadania
Jasne zdefiniowanie zadania lub funkcji, które LLM powinien wykonywać, zapewnia, że spełnia on potrzeby użytkownika, niezależnie od tego, czy chodzi o dostarczanie informacji, odpowiadanie na pytania czy inne konkretne zadanie.
Specyfikacja tonów
Określenie pożądanego tonu lub stylu odpowiedzi ustawia odpowiedni nastrój dla interakcji, czy to formalnej, przyjaznej czy informacyjnej.
Różne instrukcje
Ta kategoria może obejmować szereg dyrektyw, w tym dodawanie linków i obrazów, przekazywanie pozdrowień lub gromadzenie określonych danych.
Tworzenie adekwatności kontekstowej
Przemyślane tworzenie podpowiedzi jest strategicznym podejściem zapewniającym, że synergia między RAG i LLM skutkuje odpowiedziami, które są kontekstowo świadome i wysoce adekwatne do wymagań użytkownika, zwiększając ogólne wrażenia użytkownika.
Dlaczego warto wybrać Cody’s RAG API?
Teraz, gdy rozwikłaliśmy znaczenie RAG i jego podstawowych komponentów, przedstawmy Cody’ego jako najlepszego partnera w urzeczywistnianiu RAG. Cody oferuje kompleksowy interfejs API RAG, który łączy w sobie wszystkie niezbędne elementy wymagane do wydajnego pobierania i przetwarzania danych, dzięki czemu jest najlepszym wyborem dla Twojej podróży RAG.
Model niezależny
Nie musisz martwić się o zmianę modelu, aby być na bieżąco z najnowszymi trendami AI. Dzięki interfejsowi API RAG firmy Cody można łatwo przełączać się między dużymi modelami językowymi w locie bez dodatkowych kosztów.
Niezrównana wszechstronność
Interfejs API RAG firmy Cody wykazuje niezwykłą wszechstronność, wydajnie obsługując różne formaty plików i rozpoznając hierarchie tekstowe w celu optymalnej organizacji danych.
Niestandardowy algorytm dzielenia na części
Jego cechą wyróżniającą są zaawansowane algorytmy dzielenia na części, umożliwiające kompleksową segmentację danych, w tym metadanych, zapewniając doskonałe zarządzanie danymi.
Szybkość nie do porównania
Zapewnia błyskawiczne wyszukiwanie danych na dużą skalę z liniowym czasem zapytania, niezależnie od liczby indeksów. Gwarantuje to szybkie wyniki dla potrzeb związanych z danymi.
Bezproblemowa integracja i wsparcie
Cody oferuje płynną integrację z popularnymi platformami i kompleksowe wsparcie, zwiększając doświadczenie RAG i umacniając jego pozycję jako najlepszego wyboru do wydajnego pobierania i przetwarzania danych. Zapewnia intuicyjny interfejs użytkownika, który nie wymaga specjalistycznej wiedzy technicznej, dzięki czemu jest dostępny i przyjazny dla użytkowników na wszystkich poziomach umiejętności, dodatkowo usprawniając pobieranie i przetwarzanie danych.
Funkcje API RAG, które usprawniają interakcje z danymi
Badając Retrieval-Augmented Generation (RAG), odkryliśmy wszechstronne rozwiązanie, które integruje duże modele językowe (LLM) z wyszukiwaniem semantycznym, wektorowymi bazami danych i podpowiedziami w celu usprawnienia wyszukiwania i przetwarzania danych.
RAG, jako niezależny od modelu i domeny, jest niezwykle obiecujący w różnych zastosowaniach. Interfejs API RAG firmy Cody zwiększa tę obietnicę, oferując takie funkcje, jak elastyczna obsługa plików, zaawansowane dzielenie na części, szybkie pobieranie danych i płynna integracja. To połączenie może zrewolucjonizować zaangażowanie w dane.
Czy jesteś gotowy na transformację danych? Przedefiniuj swoje interakcje z danymi i odkryj nową erę w przetwarzaniu danych dzięki Cody AI.
Najczęściej zadawane pytania
1. Jaka jest różnica między RAG a dużymi modelami językowymi (LLM)?
RAG API (Retrieval-Augmented Generation API) i LLM (Large Language Models) działają w tandemie.
RAG API to interfejs programowania aplikacji, który łączy w sobie dwa kluczowe elementy: mechanizm wyszukiwania i generatywny model języka (LLM). Jego głównym celem jest usprawnienie wyszukiwania danych i generowania treści, silnie koncentrując się na odpowiedziach kontekstowych. RAG API jest często stosowany do konkretnych zadań, takich jak odpowiadanie na pytania, generowanie treści i podsumowywanie tekstu. Została zaprojektowana tak, aby dostarczać kontekstowo trafne odpowiedzi na zapytania użytkowników.
Z drugiej strony LLM (Large Language Models) stanowią szerszą kategorię modeli językowych, takich jak GPT (Generative Pre-trained Transformer). Modele te są wstępnie trenowane na obszernych zbiorach danych, umożliwiając im generowanie tekstu podobnego do ludzkiego dla różnych zadań przetwarzania języka naturalnego. Chociaż mogą one obsługiwać wyszukiwanie i generowanie, ich wszechstronność rozciąga się na różne zastosowania, w tym tłumaczenie, analizę nastrojów, klasyfikację tekstu i wiele innych.
Zasadniczo RAG API jest wyspecjalizowanym narzędziem, które łączy pobieranie i generowanie odpowiedzi kontekstowych w określonych aplikacjach. Z kolei LLM są podstawowymi modelami językowymi, które służą jako podstawa dla różnych zadań przetwarzania języka naturalnego, oferując szerszy zakres potencjalnych zastosowań niż tylko wyszukiwanie i generowanie.
2. RAG i LLM – co jest lepsze i dlaczego?
Wybór między RAG API i LLM zależy od konkretnych potrzeb i charakteru zadania, które chcesz wykonać. Oto zestawienie czynników, które pomogą Ci określić, co jest lepsze w Twojej sytuacji:
Wybierz RAG API If:
Potrzebujesz odpowiedzi uwzględniających kontekst
RAG API wyróżnia się w dostarczaniu kontekstowych odpowiedzi. Jeśli zadanie polega na odpowiadaniu na pytania, podsumowywaniu treści lub generowaniu odpowiedzi kontekstowych, RAG API jest odpowiednim wyborem.
Masz określone przypadki użycia
Jeśli aplikacja lub usługa ma dobrze zdefiniowane przypadki użycia, które wymagają treści kontekstowych, RAG API może być lepszym rozwiązaniem. Jest on przeznaczony do zastosowań, w których kontekst odgrywa kluczową rolę.
Potrzebujesz precyzyjnej kontroli
RAG API pozwala na precyzyjne dostrojenie i dostosowanie, co może być korzystne, jeśli masz określone wymagania lub ograniczenia dla swojego projektu.
Wybierz studia LLM, jeśli:
Wymagasz wszechstronności
Modele LLM, podobnie jak modele GPT, są bardzo wszechstronne i mogą obsługiwać szeroką gamę zadań przetwarzania języka naturalnego. Jeśli Twoje potrzeby obejmują wiele zastosowań, studia LLM oferują elastyczność.
Chcesz tworzyć niestandardowe rozwiązania
Możesz tworzyć niestandardowe rozwiązania do przetwarzania języka naturalnego i dostosowywać je do konkretnych przypadków użycia lub integrować je z istniejącymi przepływami pracy.
Potrzebujesz wstępnie wyszkolonego rozumienia języka
Maszyny LLM są wstępnie przeszkolone na ogromnych zbiorach danych, co oznacza, że od razu po wyjęciu z pudełka dobrze rozumieją język. Jeśli musisz pracować z dużymi ilościami nieustrukturyzowanych danych tekstowych, LLM może być cennym zasobem.
3. Dlaczego modele LLM, podobnie jak modele GPT, są tak popularne w przetwarzaniu języka naturalnego?
LLM przyciągnęły szeroką uwagę ze względu na ich wyjątkową wydajność w różnych zadaniach językowych. LLM są trenowane na dużych zbiorach danych. W rezultacie są w stanie zrozumieć i stworzyć spójny, odpowiedni kontekstowo i gramatycznie poprawny tekst, rozumiejąc niuanse każdego języka. Ponadto dostępność wstępnie wytrenowanych LLM sprawiła, że oparte na sztucznej inteligencji rozumienie i generowanie języka naturalnego stało się dostępne dla szerszego grona odbiorców.
4. Jakie są typowe zastosowania LLM?
LLM znajdują zastosowanie w szerokim spektrum zadań językowych, w tym:
Rozumienie języka naturalnego
LLM doskonale sprawdzają się w zadaniach takich jak analiza sentymentu, rozpoznawanie encji nazwanych i odpowiadanie na pytania. Ich solidne możliwości rozumienia języka sprawiają, że są one cenne przy wydobywaniu spostrzeżeń z danych tekstowych.
Generowanie tekstu
Mogą generować tekst podobny do ludzkiego dla aplikacji takich jak chatboty i generowanie treści, dostarczając spójne i kontekstowo odpowiednie odpowiedzi.
Tłumaczenie maszynowe
Znacząco poprawiły one jakość tłumaczenia maszynowego. Mogą tłumaczyć tekst między językami z niezwykłą dokładnością i płynnością.
Podsumowywanie treści
Są biegłe w generowaniu zwięzłych podsumowań długich dokumentów lub transkrypcji, zapewniając skuteczny sposób na wydestylowanie istotnych informacji z obszernych treści.
5. W jaki sposób LLM może być na bieżąco z nowymi danymi i ewoluującymi zadaniami?
Zapewnienie aktualności i skuteczności programów LLM ma kluczowe znaczenie. Stosowanych jest kilka strategii, aby aktualizować je o nowe dane i ewoluujące zadania:
Rozszerzenie danych
Ciągłe rozszerzanie danych jest niezbędne, aby zapobiec spadkowi wydajności wynikającemu z nieaktualnych informacji. Rozszerzenie magazynu danych o nowe, istotne informacje pomaga modelowi zachować dokładność i trafność.
Przekwalifikowanie
Okresowe ponowne szkolenie LLM z wykorzystaniem nowych danych jest powszechną praktyką. Dopracowanie modelu na podstawie najnowszych danych zapewnia, że dostosowuje się on do zmieniających się trendów i pozostaje aktualny.
Aktywna nauka
Innym podejściem jest wdrożenie technik aktywnego uczenia się. Obejmuje to identyfikację przypadków, w których model jest niepewny lub może popełniać błędy i zbieranie adnotacji dla tych przypadków. Adnotacje te pomagają udoskonalić wydajność modelu i utrzymać jego dokładność.

