
¿Qué es la API RAG y cómo funciona?
La capacidad de recuperar y procesar datos de forma eficiente se ha convertido en un factor de cambio en la era de la tecnología intensiva. Exploremos cómo la API RAG redefine el procesamiento de datos. Este innovador planteamiento combina las proezas de los grandes modelos lingüísticos (LLM) con técnicas basadas en la recuperación para revolucionar la recuperación de datos.
¿Qué son los grandes modelos lingüísticos (LLM)?
Los Grandes Modelos Lingüísticos (LLM) son sistemas avanzados de inteligencia artificial que sirven de base a la Generación Mejorada de Recuperación (RAG). Los LLM, como el GPT (Generative Pre-trained Transformer), son modelos de IA muy sofisticados y basados en el lenguaje. Se han entrenado con amplios conjuntos de datos y pueden comprender y generar textos similares a los humanos, lo que los hace indispensables para diversas aplicaciones.
En el contexto de la API RAG, estos LLM desempeñan un papel central en la mejora de la recuperación, el procesamiento y la generación de datos, lo que la convierte en una herramienta versátil y potente para optimizar las interacciones de datos.
Vamos a simplificarle el concepto de API RAG.
¿Qué es RAG?
RAG, o Retrieval-Augmented Generation, es un marco diseñado para optimizar la IA generativa. Su principal objetivo es garantizar que las respuestas generadas por la IA no sólo estén actualizadas y sean pertinentes para la solicitud de entrada, sino que también sean precisas. Este enfoque en la precisión es un aspecto clave de la funcionalidad de RAG API. Se trata de una forma innovadora de procesar datos mediante programas informáticos superinteligentes llamados Large Language Models (LLM), como GPT.
Estos LLM son como magos digitales capaces de predecir qué palabras vienen a continuación en una frase entendiendo las palabras que las preceden. Han aprendido de toneladas de texto, así que pueden escribir de una forma que suena muy humana. Con RAG, puede utilizar estos asistentes digitales para ayudarle a encontrar datos y trabajar con ellos de forma personalizada. Es como tener un amigo muy listo que lo sabe todo sobre datos y que te ayuda.
Esencialmente, el GAR inyecta datos recuperados mediante la búsqueda semántica en la consulta realizada al LLM como referencia. Profundizaremos en estas terminologías más adelante en el artículo.
Para saber más sobre la GAR en profundidad, consulta este completo artículo de Cohere
RAG vs. Ajuste fino: ¿Cuál es la diferencia?
| Aspecto | API RAG | Ajuste fino |
|---|---|---|
| Acérquese a | Aumenta los LLM existentes con el contexto de su base de datos | Especializa a LLM para tareas específicas |
| Recursos informáticos | Requiere menos recursos informáticos | Requiere importantes recursos informáticos |
| Requisitos de datos | Adecuado para conjuntos de datos pequeños | Requiere grandes cantidades de datos |
| Especificidad del modelo | Independiente del modelo; puede cambiar de modelo según sea necesario | Específico del modelo; suele ser bastante tedioso cambiar de LLM |
| Adaptabilidad de dominio | No distingue entre dominios y es versátil para diversas aplicaciones. | Puede requerir una adaptación a distintos ámbitos |
| Reducción de las alucinaciones | Reduce eficazmente las alucinaciones | Puede experimentar más alucinaciones sin una afinación cuidadosa |
| Casos de uso común | Ideal para sistemas de pregunta-respuesta (QA), diversas aplicaciones | Tareas especializadas como análisis de documentos médicos, etc. |
El papel de las bases de datos vectoriales
La base de datos vectorial es fundamental en la Generación Mejorada por Recuperación (RAG) y los Grandes Modelos Lingüísticos (LLM). Sirven de columna vertebral para mejorar la recuperación de datos, el aumento del contexto y el rendimiento general de estos sistemas. He aquí una exploración del papel clave de las bases de datos vectoriales:
Superar las limitaciones de las bases de datos estructuradas
Las bases de datos estructuradas tradicionales suelen quedarse cortas cuando se utilizan en la API RAG debido a su naturaleza rígida y predefinida. Tienen dificultades para gestionar los requisitos flexibles y dinámicos de la alimentación de información contextual a los LLM. Las bases de datos vectoriales suplen esta carencia.
Almacenamiento eficiente de datos en forma vectorial
Las bases de datos vectoriales son excelentes para almacenar y gestionar datos mediante vectores numéricos. Este formato permite una representación versátil y multidimensional de los datos. Estos vectores pueden procesarse eficazmente, lo que facilita la recuperación avanzada de datos.
Pertinencia y rendimiento de los datos
Los sistemas GAR pueden acceder rápidamente a la información contextual pertinente y recuperarla aprovechando las bases de datos vectoriales. Esta recuperación eficaz es crucial para mejorar la velocidad y la precisión de las respuestas generadas por los LLM.
Agrupación y análisis multidimensional
Los vectores pueden agrupar y analizar puntos de datos en un espacio multidimensional. Esta función tiene un valor incalculable para el GAR, ya que permite agrupar, relacionar y presentar de forma coherente los datos contextuales a los LLM. Así se mejora la comprensión y se generan respuestas adaptadas al contexto.
¿Qué es la búsqueda semántica?
La búsqueda semántica es una piedra angular de la API de Generación Mejorada de Recuperación (RAG) y de los Grandes Modelos Lingüísticos (LLM). No se puede exagerar su importancia, ya que ha revolucionado la forma de acceder a la información y comprenderla.
Más allá de la base de datos tradicional
La búsqueda semántica supera las limitaciones de las bases de datos estructuradas, que a menudo tienen dificultades para gestionar requisitos de datos dinámicos y flexibles. En su lugar, recurre a bases de datos de vectores, lo que permite una gestión de datos más versátil y adaptable, crucial para el éxito del GAR y los LLM.
Análisis multidimensional
Uno de los puntos fuertes de la búsqueda semántica es su capacidad para comprender datos en forma de vectores numéricos. Este análisis multidimensional mejora la comprensión de las relaciones de los datos en función del contexto, lo que permite generar contenidos más coherentes y conscientes de éste.
Recuperación eficaz de datos
La eficiencia es vital en la recuperación de datos, especialmente para la generación de respuestas en tiempo real en los sistemas API RAG. La búsqueda semántica optimiza el acceso a los datos, mejorando significativamente la velocidad y la precisión de la generación de respuestas mediante LLM. Se trata de una solución versátil que puede adaptarse a diversas aplicaciones, desde análisis médicos a consultas complejas, reduciendo al mismo tiempo las imprecisiones en los contenidos generados por IA.
¿Qué es la API RAG?
Piensa en la API de RAG como RAG-como-un-Servicio. Reúne todos los elementos fundamentales de un sistema GAR en un solo paquete, lo que hace que sea cómodo emplear un sistema GAR en tu organización. La API de RAG te permite centrarte en los elementos principales de un sistema RAG y dejar que la API se encargue del resto.
¿Cuáles son los 3 elementos de las consultas API RAG?

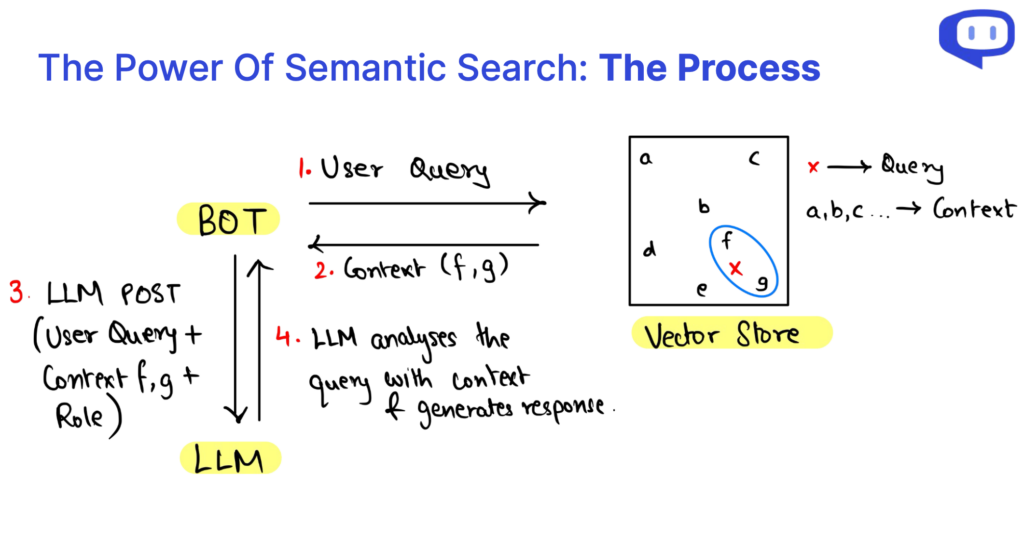
Cuando nos sumergimos en los entresijos de la Generación Mejorada por Recuperación (RAG), descubrimos que una consulta RAG puede diseccionarse en tres elementos cruciales: El contexto, la función y la consulta del usuario. Estos componentes son los pilares que sustentan el sistema GAR, y cada uno de ellos desempeña un papel vital en el proceso de generación de contenidos.
En Contexto constituye la base de una consulta a la API RAG, ya que sirve como repositorio de conocimientos donde reside la información esencial. Aprovechar la búsqueda semántica en los datos de la base de conocimientos existente permite crear un contexto dinámico pertinente para la consulta del usuario.
En Papel define el propósito del sistema GAR, dirigiéndolo a realizar tareas específicas. Guía al modelo para generar contenidos adaptados a las necesidades, ofrecer explicaciones, responder a consultas o resumir información.
En Consulta del usuario es la entrada del usuario, que señala el inicio del proceso GAR. Representa la interacción del usuario con el sistema y comunica sus necesidades de información.
El proceso de recuperación de datos dentro de la API RAG se hace eficiente mediante la búsqueda semántica. Este enfoque permite el análisis multidimensional de los datos, lo que mejora nuestra comprensión de las relaciones de los datos en función del contexto. En pocas palabras, comprender la anatomía de las consultas RAG y la recuperación de datos a través de la búsqueda semántica nos permite desbloquear el potencial de esta tecnología, facilitando un acceso eficiente al conocimiento y la generación de contenidos conscientes del contexto.
¿Cómo mejorar la pertinencia de las prompts?
La ingeniería de prompts es fundamental para dirigir los grandes modelos lingüísticos (LLM) dentro de RAG con el fin de generar respuestas contextualmente relevantes para un dominio específico.
Aunque la capacidad de la Generación Mejorada por Recuperación (RAG) para aprovechar el contexto es una capacidad formidable, proporcionar contexto por sí solo no siempre es suficiente para garantizar respuestas de alta calidad. Aquí es donde entra en juego el concepto de avisos.
Una indicación bien elaborada sirve de hoja de ruta para el LLM, dirigiéndolo hacia la respuesta deseada. Suele incluir los siguientes elementos:
Desbloquear la relevancia contextual
La generación aumentada por recuperación (RAG) es una potente herramienta para aprovechar el contexto. Sin embargo, el mero contexto puede no bastar para garantizar respuestas de alta calidad. Aquí es donde las instrucciones son cruciales para dirigir los Modelos de Lenguaje Amplio (LLM) dentro de RAG para generar respuestas que se alineen con dominios específicos.
Hoja de ruta para crear una función de bot para su caso de uso
Un aviso bien estructurado actúa como una hoja de ruta, dirigiendo a los LLM hacia las respuestas deseadas. Suele constar de varios elementos:
Identidad del bot
Al mencionar el nombre del bot, estableces su identidad dentro de la interacción, haciendo que la conversación sea más personal.
Definición de tareas
Definir claramente la tarea o función que debe realizar el LLM garantiza que satisfaga las necesidades del usuario, ya sea proporcionar información, responder preguntas o cualquier otra tarea específica.
Tono Especificación
Especificar el tono o estilo de respuesta deseados crea el ambiente adecuado para la interacción, ya sea formal, amistosa o informativa.
Instrucciones varias
Esta categoría puede abarcar una serie de directivas, como añadir enlaces e imágenes, proporcionar saludos o recopilar datos específicos.
Crear relevancia contextual
La elaboración cuidadosa de las preguntas es un enfoque estratégico para garantizar que la sinergia entre el GAR y los LLM dé lugar a respuestas contextualizadas y muy pertinentes para las necesidades del usuario, mejorando así la experiencia global de éste.
¿Por qué elegir la API RAG de Cody?
Ahora que hemos desentrañado el significado de RAG y sus componentes básicos, presentemos a Cody como el socio definitivo para hacer realidad RAG. Cody ofrece una API RAG completa que combina todos los elementos esenciales necesarios para una recuperación y un tratamiento eficaces de los datos, lo que la convierte en la mejor opción para su viaje RAG.
Modelo agnóstico
No tienes que preocuparte de cambiar de modelo para estar al día de las últimas tendencias en IA. Con la API RAG de Cody, puedes cambiar fácilmente entre grandes modelos lingüísticos sobre la marcha, sin coste adicional.
Versatilidad sin igual
La API RAG de Cody hace gala de una notable versatilidad, ya que maneja con eficacia diversos formatos de archivo y reconoce jerarquías textuales para una organización óptima de los datos.
Algoritmo de fragmentación personalizado
Su característica más destacada radica en sus avanzados algoritmos de fragmentación, que permiten una segmentación exhaustiva de los datos, incluidos los metadatos, lo que garantiza una gestión superior de los datos.
Velocidad incomparable
Garantiza una recuperación de datos ultrarrápida a escala con un tiempo de consulta lineal, independientemente del número de índices. Garantiza resultados rápidos para sus necesidades de datos.
Integración y asistencia sin fisuras
Cody ofrece una integración perfecta con las plataformas más populares y una asistencia completa, lo que mejora su experiencia con RAG y consolida su posición como la mejor opción para la recuperación y el procesamiento eficaces de datos. Garantiza una interfaz de usuario intuitiva que no requiere conocimientos técnicos, lo que la hace accesible y fácil de usar para personas de todos los niveles, agilizando aún más la experiencia de recuperación y procesamiento de datos.
Funciones de la API de RAG que mejoran las interacciones con los datos
En nuestra exploración de la Generación Mejorada de Recuperación (RAG), hemos descubierto una solución versátil que integra grandes modelos lingüísticos (LLM) con la búsqueda semántica, las bases de datos vectoriales y los avisos para mejorar la recuperación y el procesamiento de datos.
La RAG, al ser independiente del modelo y del dominio, es muy prometedora en diversas aplicaciones. La API RAG de Cody eleva esta promesa al ofrecer funciones como el manejo flexible de archivos, la fragmentación avanzada, la recuperación rápida de datos y las integraciones sin fisuras. Esta combinación está a punto de revolucionar el uso de los datos.
¿Está preparado para adoptar esta transformación de los datos? Redefine tus interacciones con los datos y explora una nueva era en el procesamiento de datos con Cody AI.
Preguntas frecuentes
1. ¿Cuál es la diferencia entre la GAR y los grandes modelos lingüísticos (LLM)?
La API RAG (Retrieval-Augmented Generation API) y los LLM (Large Language Models) trabajan en tándem.
RAG API es una interfaz de programación de aplicaciones que combina dos elementos fundamentales: un mecanismo de recuperación y un modelo generativo del lenguaje (LLM). Su principal objetivo es mejorar la recuperación de datos y la generación de contenidos, centrándose especialmente en las respuestas conscientes del contexto. La API RAG suele aplicarse a tareas específicas, como la respuesta a preguntas, la generación de contenidos y el resumen de textos. Está diseñado para ofrecer respuestas contextualmente relevantes a las consultas de los usuarios.
Los LLM (Large Language Models), por su parte, constituyen una categoría más amplia de modelos lingüísticos como el GPT (Generative Pre-trained Transformer). Estos modelos están preentrenados en amplios conjuntos de datos, lo que les permite generar textos similares a los humanos para diversas tareas de procesamiento del lenguaje natural. Aunque pueden encargarse de la recuperación y la generación, su versatilidad se extiende a diversas aplicaciones, como la traducción, el análisis de sentimientos o la clasificación de textos, entre otras.
En esencia, la API RAG es una herramienta especializada que combina la recuperación y la generación de respuestas contextualizadas en aplicaciones específicas. En cambio, los LLM son modelos lingüísticos fundamentales que sirven de base para diversas tareas de procesamiento del lenguaje natural y ofrecen una gama más amplia de aplicaciones potenciales que van más allá de la mera recuperación y generación.
2. GAR y LLM: ¿qué es mejor y por qué?
La elección entre RAG API y LLM depende de sus necesidades específicas y de la naturaleza de la tarea que pretenda realizar. Aquí tienes un desglose de las consideraciones para ayudarte a determinar cuál es mejor para tu situación:
Elija RAG API Si:
Necesita respuestas adaptadas al contexto
RAG API destaca por ofrecer respuestas contextualmente relevantes. Si su tarea consiste en responder preguntas, resumir contenidos o generar respuestas específicas para cada contexto, la API RAG es una opción adecuada.
Tiene casos de uso específicos
Si su aplicación o servicio tiene casos de uso bien definidos que requieren contenidos sensibles al contexto, la API RAG puede ser más adecuada. Está diseñado para aplicaciones en las que el contexto desempeña un papel crucial.
Necesita un control preciso
La API RAG permite realizar ajustes y personalizaciones, lo que puede resultar ventajoso si tiene requisitos o limitaciones específicos para su proyecto.
Elige un LLM si:
Necesita versatilidad
Los LLM, al igual que los modelos GPT, son muy versátiles y pueden manejar una amplia gama de tareas de procesamiento del lenguaje natural. Si sus necesidades abarcan varias aplicaciones, los LLM ofrecen flexibilidad.
Quiere crear soluciones a medida
Puede crear soluciones personalizadas de procesamiento del lenguaje natural y ajustarlas a su caso de uso específico o integrarlas en sus flujos de trabajo existentes.
Necesita una comprensión lingüística preformada
Los LLM vienen preentrenados en amplios conjuntos de datos, lo que significa que tienen una gran comprensión del lenguaje desde el primer momento. Si necesita trabajar con grandes volúmenes de datos de texto no estructurados, los LLM pueden ser un activo valioso.
3. ¿Por qué los LLM, al igual que los modelos GPT, son tan populares en el procesamiento del lenguaje natural?
Los LLM han suscitado una gran atención por su excepcional rendimiento en diversas tareas lingüísticas. Los LLM se entrenan con grandes conjuntos de datos. Como resultado, pueden comprender y producir textos coherentes, contextualmente relevantes y gramaticalmente correctos, entendiendo los matices de cualquier lengua. Además, la accesibilidad de los LLM preentrenados ha puesto al alcance de un público más amplio la comprensión y generación de lenguaje natural mediante IA.
4. ¿Cuáles son algunas aplicaciones típicas de los LLM?
Los LLM encuentran aplicación en un amplio espectro de tareas lingüísticas, entre ellas:
Comprensión del lenguaje natural
Los LLM destacan en tareas como el análisis de sentimientos, el reconocimiento de entidades con nombre y la respuesta a preguntas. Sus sólidas capacidades de comprensión del lenguaje las hacen valiosas para extraer información de los datos de texto.
Generación de texto
Pueden generar texto similar al humano para aplicaciones como chatbots y generación de contenidos, ofreciendo respuestas coherentes y contextualmente relevantes.
Traducción automática
Han mejorado considerablemente la calidad de la traducción automática. Pueden traducir textos entre lenguas con un notable nivel de precisión y fluidez.
Resumir contenidos
Son expertos en generar resúmenes concisos de documentos o transcripciones extensos, lo que constituye una forma eficaz de destilar la información esencial de un contenido extenso.
5. ¿Cómo pueden los LLM mantenerse al día con datos frescos y tareas en evolución?
Garantizar que los LLM sigan siendo actuales y eficaces es crucial. Se emplean varias estrategias para mantenerlos actualizados con nuevos datos y tareas en evolución:
Aumento de datos
El aumento continuo de los datos es esencial para evitar la degradación del rendimiento derivada de una información obsoleta. Aumentar el almacén de datos con información nueva y relevante ayuda al modelo a mantener su precisión y pertinencia.
Reentrenamiento
El reentrenamiento periódico de los LLM con nuevos datos es una práctica habitual. El ajuste del modelo con datos recientes garantiza su adaptación a los cambios de tendencia y su actualización.
Aprendizaje activo
Otro enfoque es aplicar técnicas de aprendizaje activo. Esto implica identificar los casos en los que el modelo es incierto o puede cometer errores y recopilar anotaciones para estos casos. Estas anotaciones ayudan a perfeccionar el rendimiento del modelo y a mantener su precisión.

